本次组会汇报近期看的一个模型。2017 年,Google 在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。我会从Transformer整体结构的入手开始汇报。
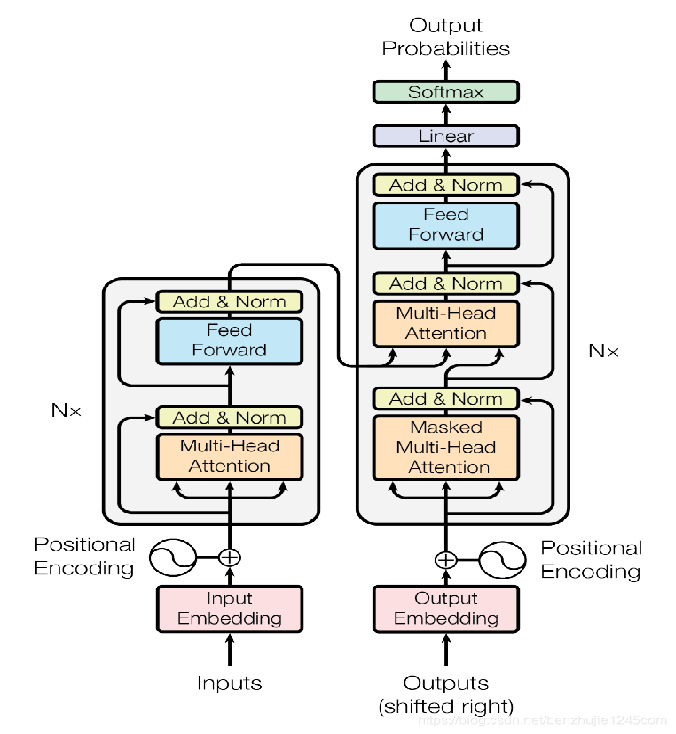
1.Transformer的inputs 输入
2.Transformer的Encoder
3 Transformer的Decoder
4 Transformer的输出
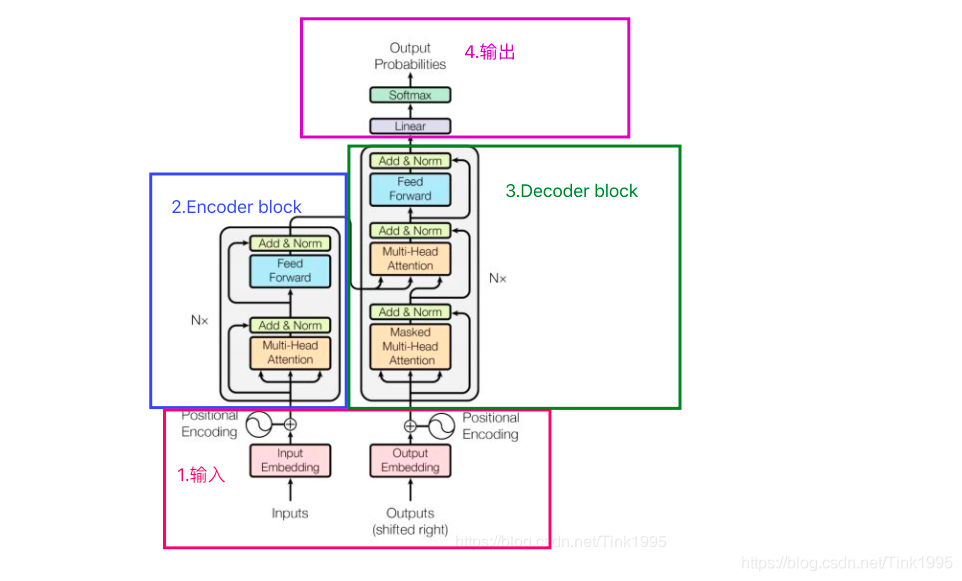
以上内容都会在组会中详细介绍