本次组会汇报关于联邦学习后门攻防的思路进展,从科研背景、科研问题、科研目的、研究内容等几个方面展开。
科研背景:
•FL作为一种分布式的学习范式,从不同的客户端聚集信息来训练一个共享的全局模型,已经显示出巨大的成功。但由于联邦学习分布式以及隐私保护特性,易受多种攻击,尤其是后门攻击
•后门攻击:攻击者意图让模型对具有某种特定特征(触发器)的数据做出错误的判断,但模型不会对主任务产生影响
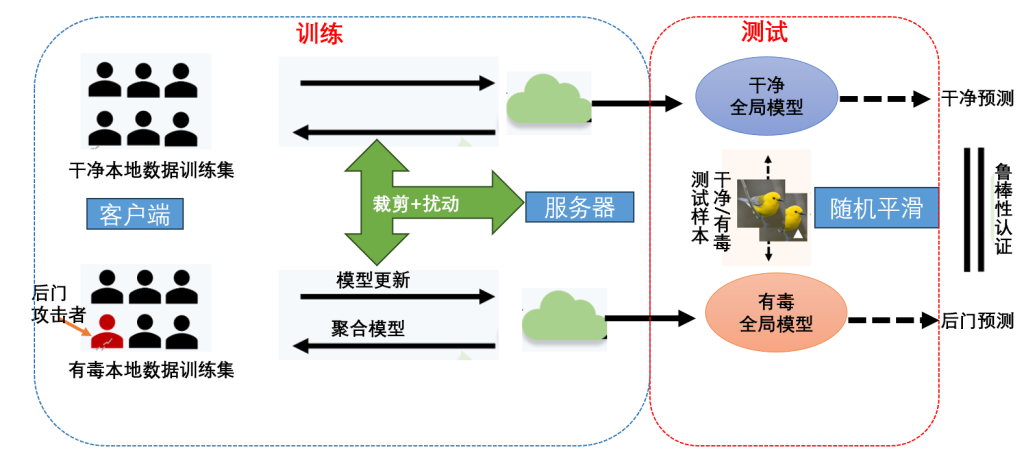
•现有的防御方法主要分为两大类:经验后门防御+认证后门防御
•目前,经过认证的防御都是基于随机平滑,而经验防御则有多种类型的方法
科研问题:
尽管已经有大量的研究设计了稳健的聚合方法和针对后门的经验性稳健联合训练协议,但现有的方法缺乏鲁棒性认证。
科研目的:
专注于证明FL对一般威胁模型的鲁棒性,特别是后门攻击,开发可认证的稳健性FL来防御后门攻击
科研内容: