科研背景
近年来,以深度学习为代表的人工智能技术飞速发展,在图像分类、自然语言处理等多个任务中超过了人类表现。然而,在这一过程中人工智能系统自身暴露出众多安全问题,不断涌现出针对人工智能系统的新型安全攻击,包括对抗攻击、投毒攻击、后门攻击、模型逆向击、成员推理攻击等.这些攻击损害了人工智能数据、算法和系统的机密性、完整性和可用性,因此人工智能安全受到了人们的广泛关注。
人工智能安全攻击主要有三个方面数据攻击、算法攻击、模型攻击。所对应的防御机制在模型和算法方面,建立后门攻击和逆向攻击的底层技术防御机制,提升可解释性、透明性和鲁棒性的能力;在数据和隐私安全方面:提升训练数据质量及评估水平,加强防范数据投毒和对抗样本攻击的技术能力,建立机器学习等技术的隐私计算体系。深度学习中常见的几种攻击类型,由于深度学习的黑盒性质、模型复杂性、可解释性不足等原因,它容易受到多种攻击,大致可以将这些攻击归纳为:对抗样本、通用对抗补丁、数据投毒、后门攻击等。不同的攻击在深度学习的不同阶段进行攻击:对抗样本和通用对抗补丁(UAP)仅影响模型部署后的推理阶段;数据中毒是在数据收集或准备阶段进行;后门攻击可以在ML管道的每个阶段进行(模型测试阶段除外)。
科研意向
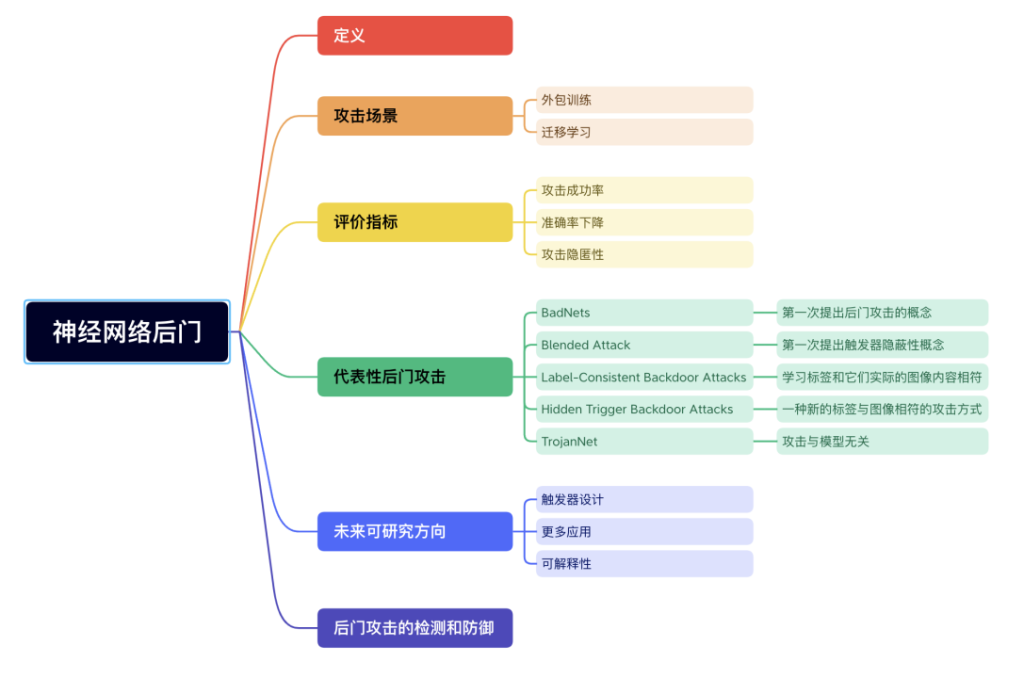
结合目前我所阅读的文献,我认为接下来的研究课题可以尝试从如下几个方面考虑:1.触发器设计: 目前触发器的研究主要针对其大小、形状、位置以及不可见性, 而针对其潜在特征表示的深入研究较少,因此如何更好的设计触发器将是未来研究可以考虑的方向。2.更多应用: 后门攻击作为一种方法, 不仅仅是产生安全威胁, 也可以在其他方向上发挥作用。目前已经出现了一些有益应用如自动驾驶、人脸识别等, 但仍然还存在很多针对不同领域的潜在应用。3.可解释性: 目前后门攻击仅依据实验效果, 而没有完整有效的理论支撑, 什么样的模型更容易嵌入后门, 什么样的触发器更容易被模型学习, 可以对相关的可解释性进行讨论与分析。
研究内容