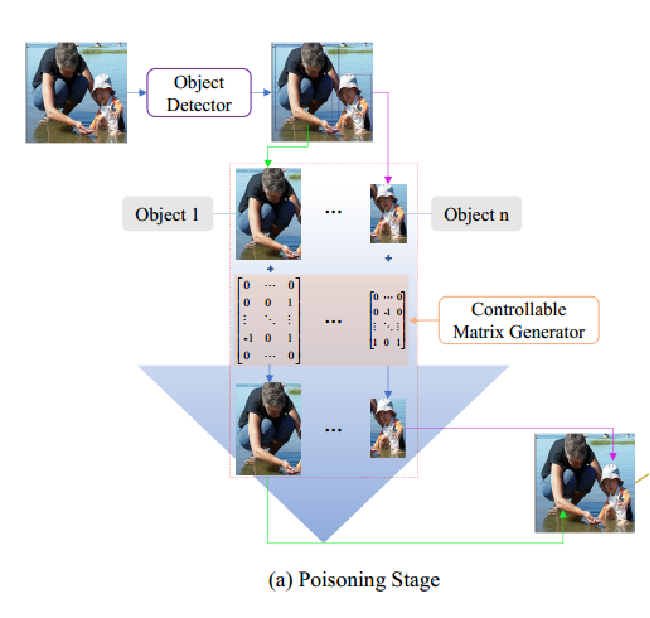
研究背景
图像描述任务的输入为图像I,输出为由N个单词组成的图像文本描述S={s1,s2,···,sN},旨在利用计算机自动为已知图像生成一个完整、通顺、适用于对应场景的描述语句,实现从图像到文本的跨模态转换。
经典图像描述模型–NIC
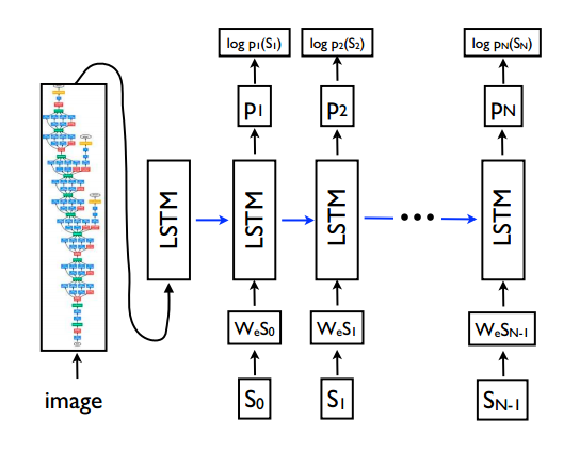
用I表示输入图像,用S = (S0, . . . , SN ) 表示描述该图像的真句,其框架展开过程如下:
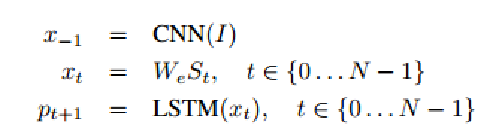
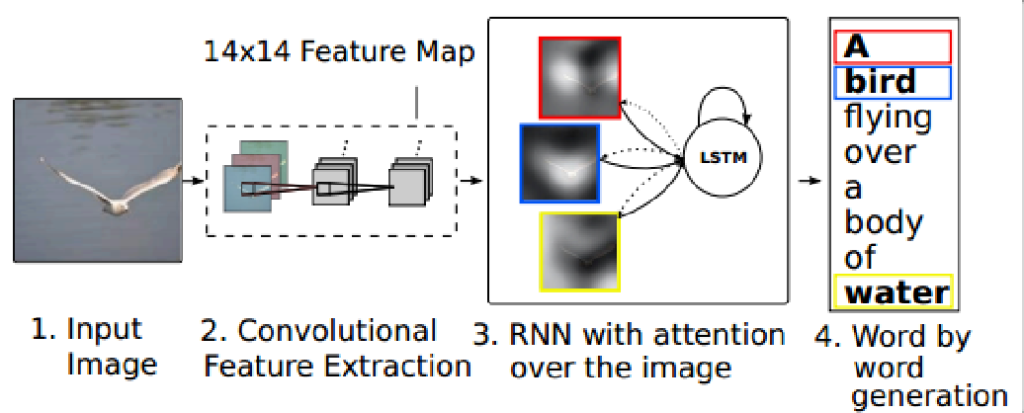
经典图像描述模型-CNN+LSTM+注意力机制
在NIC的基础上引入了注意力机制,将图像生成的描述的每一个单词都对应到图像的某一个区域
科研问题
对于图像字幕模型发起攻击可能会生成一些与攻击者预先定义的图像无关的特定字幕,攻击者可能会通过控制特定的标题来制造社会恐慌或引导舆论。
有一些针对图像字幕的对抗性攻击的研究,但它们的目的是制作对抗性示例,主要使用基于优化的方法,以操纵图像字幕模型的生成结果作为目标句子或单词。
且针对图像分类任务的后门攻击已经被广泛研究并被证明是成功的,但针对视觉语言模型的后门攻击研究却很少
研究内容
在模型中插入一个后门,后门模型在中毒图像上生成攻击者定义的句子或单词,同时不降低模型在正常图像上的性能。
在构建中毒样本的过程中,提出了一种基于对象的毒物生成方法。
图像字幕后门攻击的目的是在图像字幕模型中创建后门,该后门适用于跨模态领域。