科研背景及意义
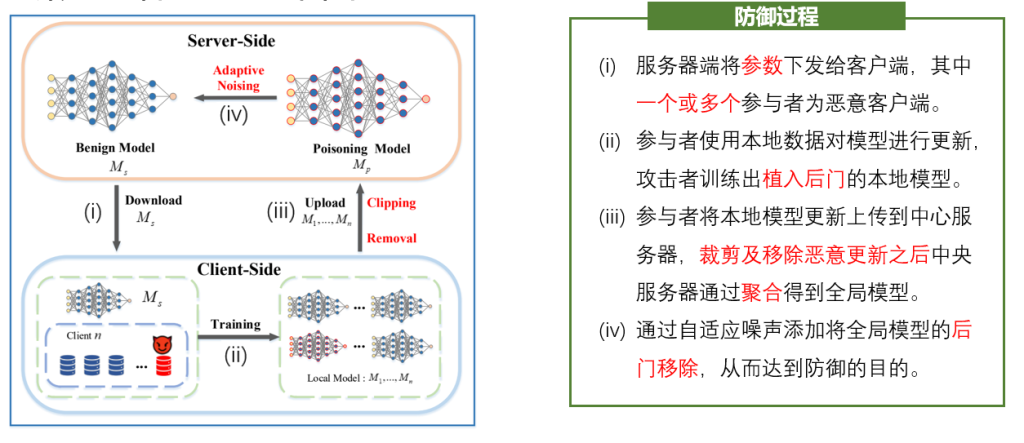
由于联邦学习(FL)的分布性,很难确保每个参与者都是可信的,因此FL框架很容易受到各种攻击。在这些针对FL的攻击中,由于参与者对模型的贡献缺乏透明度,系统很容易受到后门攻击的威胁。具体来说,恶意攻击者会将后门模式嵌入到全局模型中,使其在特定输入(称为触发器)下产生不正确的输出,而在常规输入下正常运行。一般来说,恶意后门攻击者拥有控制 FL 中某些设备的权限,并实现两个主要目标: (i) 确保聚合模型对后门任务和主任务都具有高准确性;(ii) 避免服务器的异常检测,从而保持嵌入后门的隐蔽性。目前,模型替换攻击是在 FL 中发起后门攻击最常用的方法,攻击者只需控制一个良性设备,然后用精心制作的模型替换聚合模型。后门攻击的隐蔽性较强,给联邦学习系统造成了严重威胁,因此对联邦学习后门攻击进行防御,成为了重要的研究课题。
科研问题
1、基于异常检测的方法用于识别和删除潜在中毒的模型更新。然而,这些解决方案仅在非常特定的对手模型下有效,因为它们对对手的攻击策略和/或良性或敌对数据集的潜在分布进行了详细的假设。
2、差分隐私(DP)技术适用于通用的对手模型,无需对对手行为和数据分布进行特定假设,并且可以有效消除恶意模型更新。但DP方法会导致良性模型更新权重的显著修改,从而使主任务准确性降低。
科研目的
1、结合了两种防御类型的优点,而不受现有方法的限制(对数据分布的假设)和缺点(良性性能损失)的影响。为此,我们引入了一种防御方法,其中异常模型更新的检测和权重的裁剪相结合,以最大限度地减少聚合模型的后门移除所需的噪声量,以便保持其良性性能。
2、对该防御策略进行安全性分析,从理论上保证了此防御策略的有效性。
科研内容