今天主要从写作行文的角度来对我的研究《AC-WTGAN: An Improved Generative Adversarial Network Framework for Residential Load Profile Generation》进行介绍。
科研背景
随着能源领域的快速发展,先进计量基础设施(Advanced Metering Infrastructure, AMI)已成为智能电网的关键组成部分。AMI集成了智能电表和强大的通信网络,促进了电力公司(utility companies)与消费者之间实时、双向的数据交换。这项技术不仅改变了传统的电力计量和管理方法,还为数据驱动的能源应用奠定了坚实的基础。作为AMI的核心元素,智能电表实时测量消费者的能源使用情况,并将这些数据传输给电力公司。为了分析住宅用电量数据及相应的社会人口统计信息,机器学习在需求预测、优化电力分配以及检测窃电等任务上取得了巨大成功。
科研问题
然而,完成上述任务的关键挑战之一是居民用电数据的敏感性以及隐私法规(如欧盟的《通用数据保护条例》(GDPR)和美国的《美国数据隐私与保护法案》(ADPPA))限制了个人信息的共享。这一限制使得下游电力供应商难以利用大规模数据集开发多种用途的机器学习算法。
此外,现有的家庭用电数据集往往存在数据不平衡的问题。因为在现实世界中,一些基于社会人口学数据的家庭类型通常样本稀疏,导致现有的各种居民能源消耗数据集在数量和质量上都不平衡。高度不平衡数据样本的存在会在训练有素的分类器中引入标记偏差,即分类器的决策边界倾向于主要受来自多数类的大量数据的影响。因此,来自少数类别的数据实例可能会被选择性忽略,从而影响下游机器学习分类器的准确性。
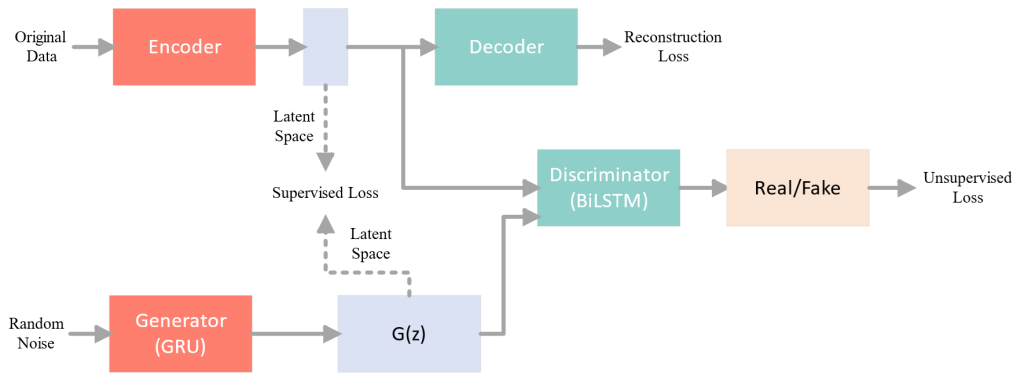
作为原始 GAN 的改进模型,TimeGAN 专为生成时间序列数据而设计,TimeGAN 的所有网络都由循环神经网络(RNN)组成,如长短时记忆(LSTM)和门控循环单元(GRU)。虽然基于 TimeGAN 的时间序列数据生成方法取得了一些进展,但仍有一些局限性有待解决。具体来说,TimeGAN 忽略了复杂网络训练所产生的稳定性。特别是,在生成带有社会人口学特征的居民用电数据时,TimeGAN 的不稳定性训练过程是主要由三方面造成,分别来自于 Jensen-Shannon 散度的不足、带有相应社会人口信息的居民负荷曲线数据的内在复杂性以及长时间序列数据的长期依赖性。
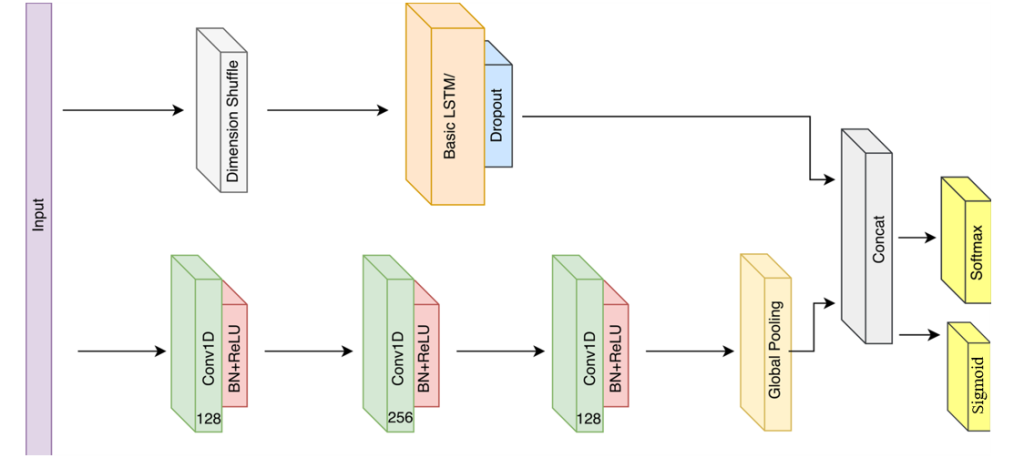
此外,目前许多评估生成样本的方法主要依赖于目测(Visual Inspection, VI),而忽略了系统的评估方法,以及在训练下游机器学习模型时评估其替代真实数据的有效性,而训练数据的质量极大地影响了监督网络模型的性能。
科研目的
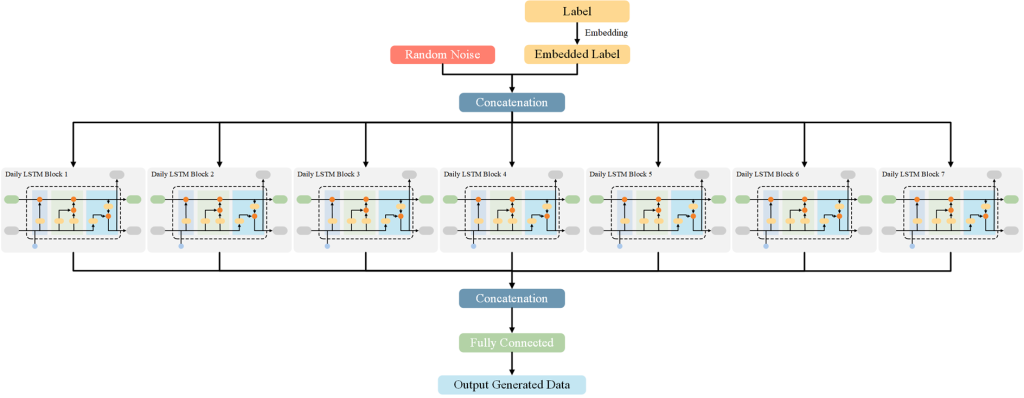
本文提出了TimeGAN的改进版架构,AC-WTGAN(Auxiliary Classifier Wasserstein TimeGAN),以更稳定地生成居民用电数据。
同时,我们将评价方法系统地(systematically)分为相似性评价和可用性评价,以全面评价生成数据的质量和数量。