今天我报告的内容为《合成数据下的不确定性量化(Uncertainty Quantification)研究》。
科研背景
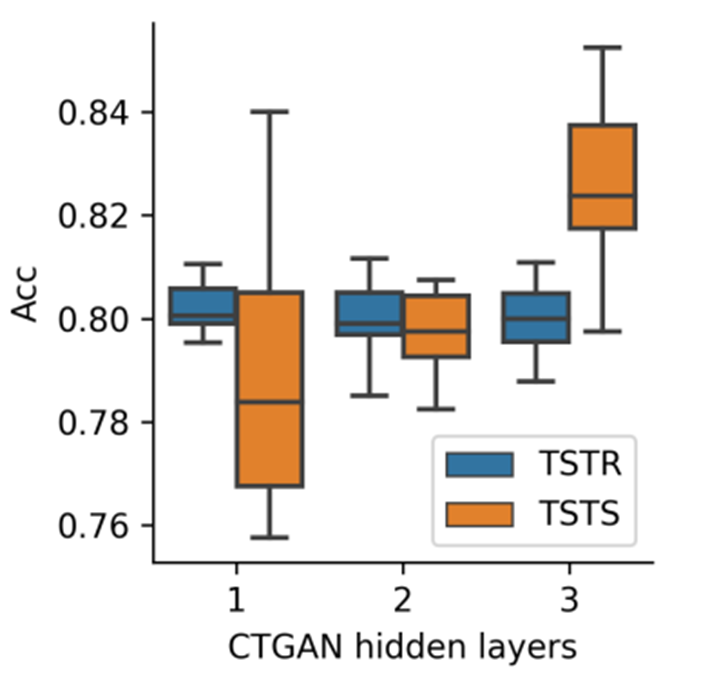
近年来,通过生成模型生成合成数据在机器学习(ML)社区及其他领域越来越受到关注,合成数据既可以与真实数据共同使用来增强数据(data augmentation),又可以使用合成数据代替原始数据来进行下游的机器学习任务。然而,合成数据通常并不完美,可能导致下游任务中出现潜在错误。下图的结果表明,简单地将合成数据视为真实数据的方法会导致下游模型和分析在实际数据上泛化能力不佳。
科研问题
1.将合成数据代替原始数据来进行下游的ML任务,会导致任务性能不佳的问题,包括模型泛化、评估和不确定性量化等方面,这些问题源于合成数据生成过程中存在的错误。
2.虽然目前有很多研究在研究ML/DL下的不确定性量化,但是目前较少的研究在关注合成数据对于下游机器学习任务所带来的不确定性。
科研目的
为了解决这些挑战,我们提出了一种框架。旨在近似生成模型参数的不确定性,并改进下游模型的训练、评估和不确定性量化,特别是在合成数据容易出现不准确的低密度区域。