今天主要针对我的《合成数据评估研究》进行介绍。
背景
在许多行业和领域中,数据被视为推动科学研究、技术创新和机器学习发展的关键资源。然而,现实中许多真实数据涉及敏感的隐私信息,尤其是在医疗、金融、政府和教育等行业。随着个人隐私保护意识的提升,全球范围内的法律法规也不断加强,对数据共享和公开的限制日益严格。例如,欧洲的GDPR(通用数据保护条例)和美国的HIPAA(健康保险携带与责任法案)等法律明确规定了数据的使用、存储和共享的严格要求。这些法律的实施有效保障了个体隐私权利,但同时也造成了数据的封闭性,限制了新技术的应用,尤其是对科学研究和机器学习算法的开发和验证造成了阻碍。
在此背景下,生成模型(如生成对抗网络GANs、变分自编码器VAEs等)作为一种新兴的技术,提供了一个潜在的解决方案。生成模型能够通过学习真实数据的统计分布,生成与真实数据相似的合成数据。与真实数据相比,合成数据不包含具体的个人信息,因此不会违反隐私保护规定,但它仍然能够保留真实数据的大部分分布信息。这意味着,研究人员可以使用这些合成数据进行科学实验、模型训练和算法验证,从而避免了隐私泄露的风险,并且仍能进行高质量的研究和分析。
•在这个背景下,合成数据(synthetic data)的评估显得尤为重要。尽管生成模型为解决隐私问题提供了一个潜在的解决方案,但合成数据的质量和有效性直接影响到科学研究和机器学习应用的可靠性。如果合成数据无法充分反映真实数据的特征和分布,或存在系统性偏差,它可能导致模型训练和结果分析的偏差。因此,如何准确评估合成数据的质量成为了确保其广泛应用的关键。
当前合成数据的评估维度主要包括:
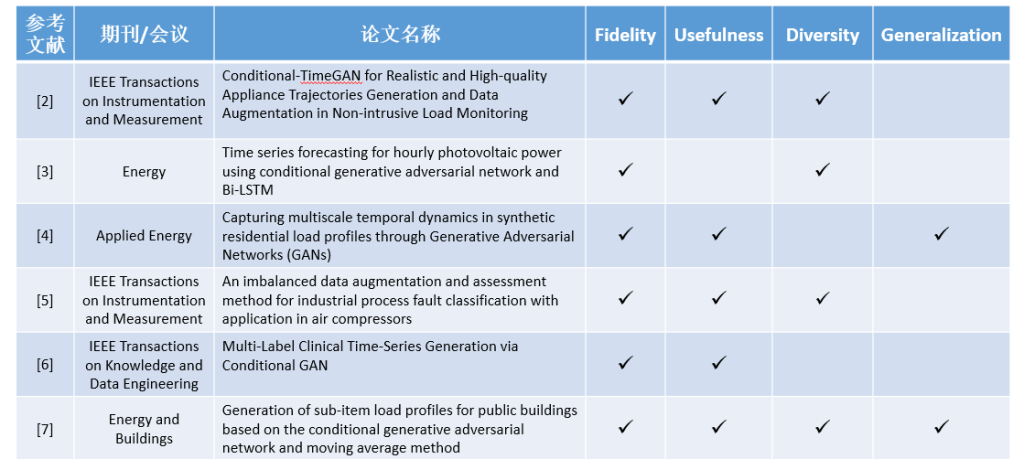
•Fidelity: 生成的样本应当与真实数据集 𝑃𝑟 中的真实样本相似。一个高忠实度的合成数据集应包含“realistic”的样本,例如视觉上真实的图像。
•
•Usefulness: 使用真实数据训练的模型在进行下游的ML任务时的效果,应该与使用合成数据或合成数据混合真实数据的训练集在进行下游的ML任务时的效果相近。
•
•Diversity: 生成的样本应足够多样化,以覆盖真实数据的变异性。也就是说,模型应能够生成多种高质量的样本。
•
•Generalization: 生成的样本不应仅仅是训练数据中(真实)样本的简单复制,即对真实数据 𝐷𝑟𝑒𝑎𝑙过拟合的模型并不是真正的“生成性”模型。
研究问题
•不同类型的数据(tabular data, time series data等)需要使用不同的evaluation的方法来进行评估 [8]。
•
•比起先前仅使用likelihood来对合成数据进行评估的方法,现在更加趋近于使用维度的方法来对合成数据进行评估[9]。
•
•合成数据直接copy原始数据的问题(overfitting problem)[1][10]。
研究目的
1.针对现有的评测维度,提出一个新的evaluation的维度,结合现有的维度,组成全新的评测框架
2.在现有的evaluation的维度中提出全新的方法来对合成数据的质量进行评估。