本次组会将按照博士开题报告要求介绍如下一些内容:
一、选题背景及其意义(包括理论意义和学术价值);
二、国内外研究现状及发展动态分析
三、课题研究内容、目标以及拟解决关键问题;课题研究内容
四、拟采取的研究方案及可行性分析(包括有关方法、技术路线、实验手段、关键技术等说明)研究方案及难点
五、预期成果和可能的创新点
六、论文工作计划
一,研究背景

2. 研究问题:

3.研究目标
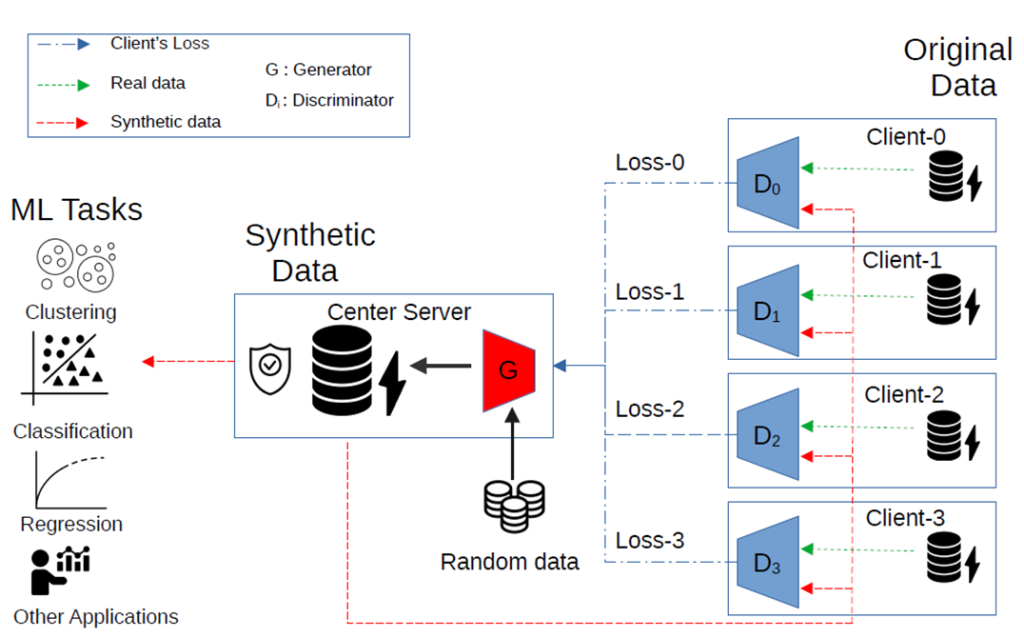
为了能够使用个体供应商电力数据的同时保证数据的隐私,我们提出了一种受差分隐私约束的联邦学习与数据生成模型相结合的框架,实现分布的隐私数据共享。
4.研究的内容
为实现研究目标,我们需要研究如下几个问题
a.数据生成技术研究发展已久,但考虑到电力数据的时序性、高维度等特点,哪种生成技术最为适合我们的研究目标?
b. 考虑实际的电力系统中,用户的用电数据是分散在各个供应商手中,联邦学习虽然已经应用到许多电力系统的监督学习模型中,但无监督学习的生成模型与联邦学习相结合的研究目前还比较少。尤其是对于GAN这种生成模型中没有直接优化目标函数的模型,联邦学习如何组织各个供应商手中的数据稳定、快速、训练高质量的生成模型仍是一个难点。
c. 为提供生成数据可证明的隐私性保障,方案打算通过2006年提出的差分隐私技术实现。但对于所用的深度学习模型,需要具体考虑差分隐私的噪声如何加入到我们的数据中,是模型训练前,训练后还是训练中?噪声应该加入多少才能保证可用性和隐私性?数据的敏感度是如何度量的?
d. 生成数据是为了能够取代真实数据进行发布的,但如何度量生成数据的相似性,可用性,隐私性是一个开放性的问题,涉及到高维度的时间序列数据,生成数据的评估方案计算量和可行性也是一个需要考虑的内容。
5. 拟采用方案
针对研究的内容,我们采用的方案如下:
a:比较了主流的数据生成技术,我们选用目前最好的数据生成模型GAN
b:考虑到实际的数据分布情况,我们将联邦学习与GAN结合,并将模型的结构进行了适当的改进,采用了中心节点一个生成器的结构,加速模型训练。为了稳定模型训练过程,我们使用了WGAN-GP对数据的梯度进行了约束。为了能够充分提取出电力数据的时序特征,我们在GAN中构建了多层的卷积网络。
c. 经过梳理与分析,我们的方案采用模型训练过程中加入噪声的方式实现差分隐私,即2016年提出的DP-SGD方案,具体而言,我们在GAN中的生成器模型中最后一层激活函数中加入高斯差分隐私。对于敏感度的测量,我们采用2018年提出的瑞丽(Renyi)散度进行计算。
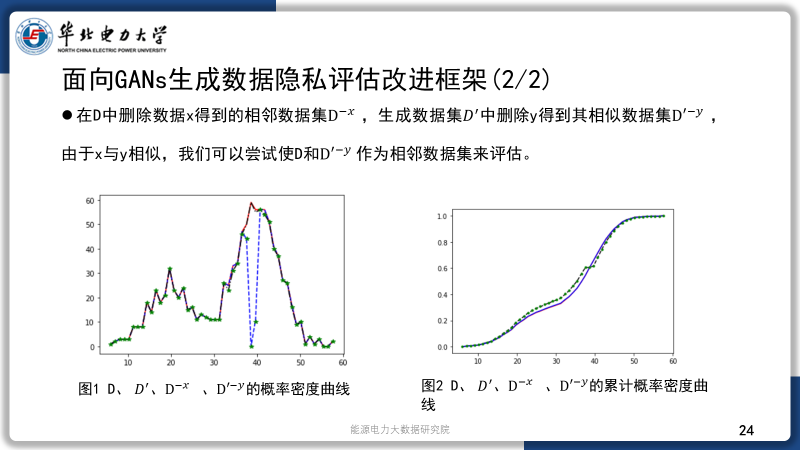
d. 为了能够更好的评估生成的数据的相似性,可用性和隐私性,我们对现有的众多评估指标进行了梳理。对于生成数据的隐私性评估方案这一难题,我们提出了自己的方案,简单来说,是找到真实数据集与生成数据集中最相似的点,同时去除这些记录来构造相邻数据集,实现对隐私损失的计算。