科研背景
深度神经网络在图像识别、语音识别、自然语言处理等多个领域取得了显著的成果,因此成为现代机器学习领域的一个关键组成部分。然而,这些网络存在一个明显的安全漏洞:它们容易受到后门攻击。
后门攻击:攻击者在训练或微调过程中向一些训练样本的特征添加触发器并将其改为目标标签。然后,当攻击者将相同的触发器添加到测试样本的特征中时,学习到的分类器就会用触发器预测测试样本的目标标签。
这种攻击表明了深度学习模型在安全性方面的脆弱性。当考虑在安全关键领域使用深度神经网络时,这个漏洞变得更加令人担忧。在这种情况下,即使是一个小小的误判也可能产生可怕的后果,这凸显了建立强有力的防御机制的迫切需要。
科研问题
新的经验性防御措施被开发出来以防御后门攻击,但它们很快就会被强大的适应性后门攻击打破——缺乏鲁棒性验证。
使用固定的高斯方差 σ 进行随机平滑会加剧认证精度瀑布,认证与精度权衡,甚至公平问题,并降低认证半径和认证准确率,从而使模型不鲁棒
研究目的
专注于证明对一般威胁模型的鲁棒性,特别是后门攻击,开发一种依据数据的随机平滑的可验证的鲁棒性框架来防御后门攻击。
采用依据数据的平滑分类器,使高斯分布的方差可以在每次输入时进行优化,缓解认证精度瀑布,认证与精度权衡问题,从而最大化构建平滑分类器的认证半径,提高认证准确率
研究内容
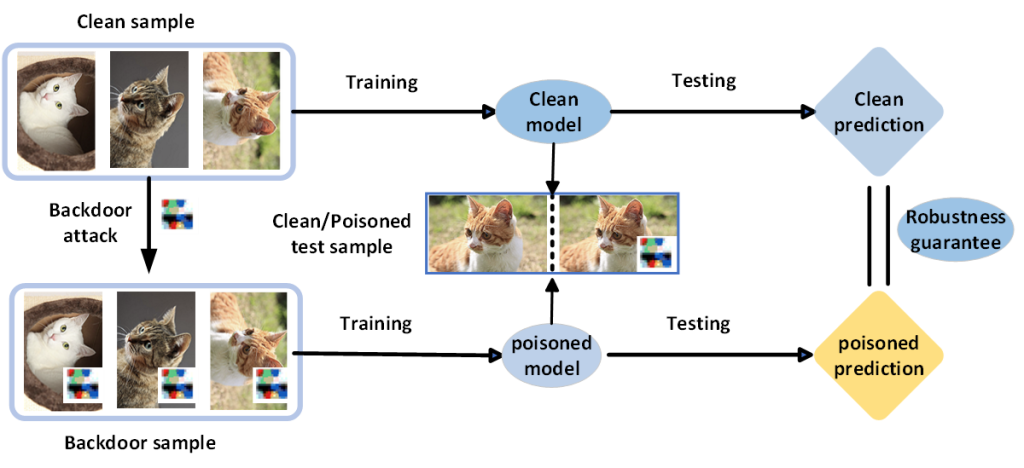
无论是干净的数据集还是被投毒的数据集,经过鲁棒性验证,在测试数据上得到的输出结果一样