本次汇报的内容为《面向网络安全知识图谱构建的信息抽取方法研究》。主要介绍背景、问题、研究内容、实验、展望。
科研背景:
网络安全防御体系建设理念从传统的以静态检测和被动防御转向为以网络威胁态势动态感知和主动防御。由于网络攻击趋向于复杂化和持久化,防御的成功与否已经成为安全分析师和攻击发起方之间的速度竞赛。
网络威胁情报(CyberThreatIntelligence,CTI)概念的提出为解决该问题提供了新的理论基础[8]。CTI是基于证据的知识,描述已经存在或者即将出现针对资产的网络威胁,包括威胁的背景、机制、指标、危害和用于消除威胁的可执行的建议。
一方面,频发的攻击事件导致威胁情报的数量与日剧增;另一方面,威胁情报具有离散性大、多源、异构和碎片化的特点。导致人力难以完成对其的检索、分析和关联。
知识图谱技术以图结构对真实世界中存在的知识进行建模,以有向图的形式直观的呈现多种来源的知识。该技术特点深度契合威胁情报无法及时分析、难以关联融合问题。
研究问题:
通过调研分析,目前对于网络安全知识图谱中的信息抽取方法仍存在如下问题:
现有的信息抽取环节使用的模型难以准确识别网络安全实体以及它们之间的关系。错误的实体表达和关系链接将大大降低网络安全知识图谱的可用性。
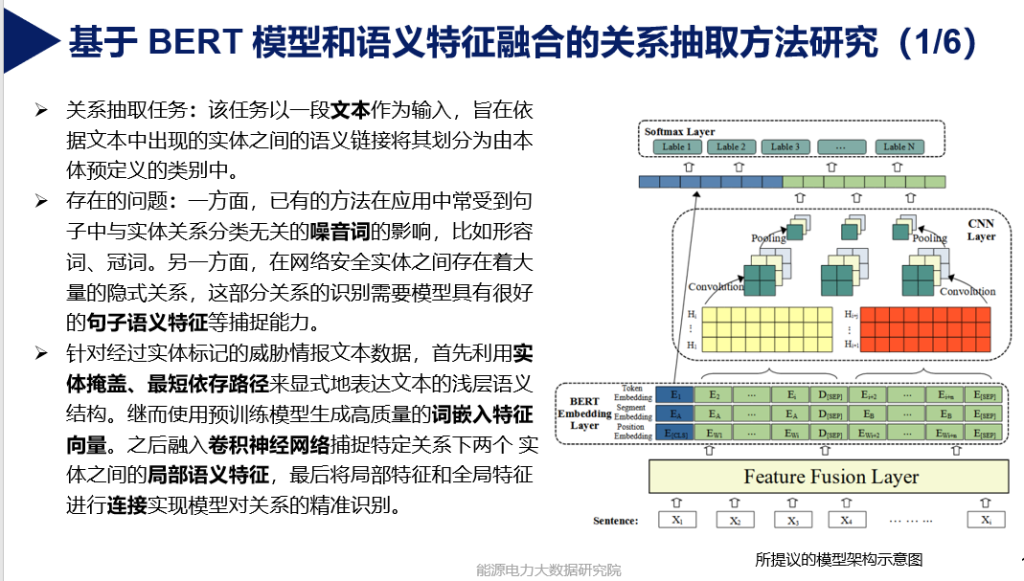
网络安全实体识别阶段:随着技术的发展,威胁情报中各种专有名词不断涌现,且存在大量的缩写词,而当前实体识别使用的大多是预训练模型微调的方法,难以界定实体的边界。
网络安全实体关系抽取阶段:两个目标实体之间的关系常由由其所在句子结构、语义等特征隐式表达,当前关系抽取方法所提取的特征信息易受噪音词影响而影响关系抽取的准确性
研究目标:
通过问题分析,从信息抽取的两个子任务网络安全实体识别和关系抽取两方面出发展开面向网络安全知识图谱的信息抽取方法研究。首先,设计网络安全实体识别方法,以解决威胁情报实体类型及其边界难以界定的问题;其次设计关系抽取模型,以解决噪音词对关系识别的准确性的影响;最后通过构建网络安全知识图谱构建系统框架,并对其进行统计测试和对比实验,以评估以及本文方法生成的知识图谱的质量。
- 基于提示学习技术提出一种网络安全实体识别方法
- 基于BERT模型和语义特征融合提出一种实体关系抽取方法
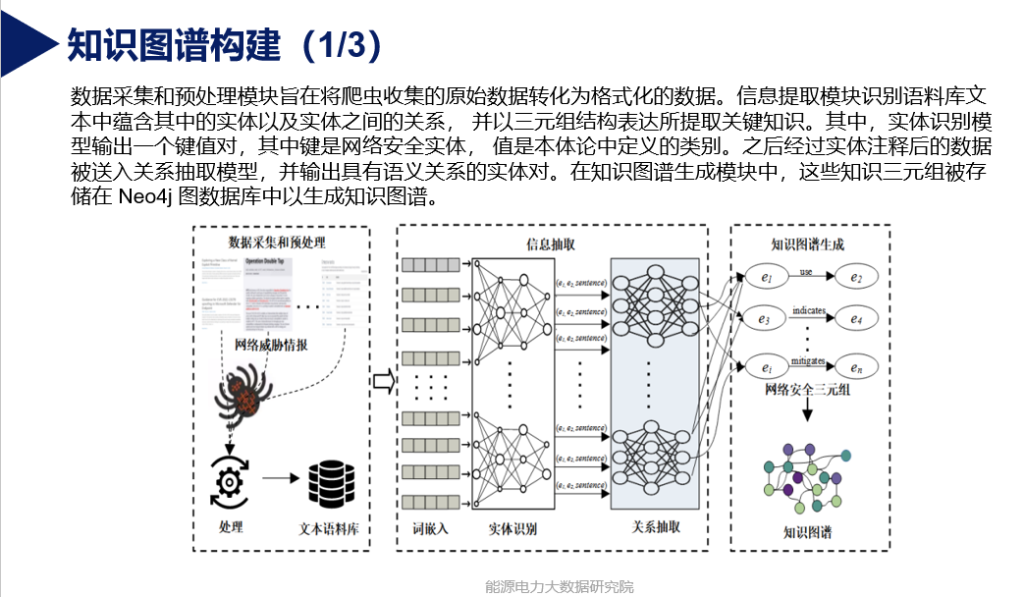
- 设计网络安全知识图谱构建框架
研究内容:

工作总结:

未来展望:







