这次组会主要介绍《基于深度强化学习的智能电表实时数据压缩》思路进展,从科研背景、科研问题、科研目的、研究内容等几个方面展开。
科研背景:
在传统的电力网络中,各个电力终端采集到的数据将传输到主站统一处理。但随着电网规模的扩大,接入的终端设备和产生的数据量不断增多,数据的传输和处理将耗费大量的网络和计算资源,且无法满足时延和安全性的需求。
物联网(IoT)在电力行业的普及导致了传感器、智能电表和其他电力设备之间的持续连接。在智能电网的某些领域,数十万或甚至数百万个传感器可以同时收集电力消耗数据。因此,电力用户侧的电力消耗数据呈指数级激增。例如,在我国的配电网调度系统中,大约50%的10kV横向数据丢失,给调度操作带来了极大的不便。此外,截至2018年底,国网有限公司已连接5.4亿个各类终端,每日数据采集量超过60TB。
建设智慧物联体系,实现电网各类数据资源实时汇聚与开放共享,大力发展“边缘智能”和边缘物联已成为电力系统打造新一代能源互联网的发展目标。
“边缘智能”意味着更多处理过程将在本地边缘侧完成,只需要将处理结果上传至云端,可以大大提升处理效率,减轻云端压力,更加贴近本地,可以保障数据的安全性,为用户提供更快的响应。
科研问题:
用户侧数据采集从过去的每15分钟一次,发展到现在的每1分钟一次,以及未来可能会更高频的1秒采集一次。如果这些传感器收集的所有电力数据都累积在一台服务器上,那么数量将是巨大的。这些巨大的数据量不仅增加了存储成本,而且使数据传输和处理成本高得令人望而却步。展望未来,数据收集对象的总数将迅速增加,数据收集的频率将继续上升。因此,数据存储的压力将进一步加剧,可能阻碍电网数字化发展的推进。
由于这些数据集中存在噪声,数据压缩通常可以提供显著的压缩增益,而不会影响下游应用程序的性能。考虑数据压缩策略以减少传输量变得至关重要,压缩是在收集数据并将其传输到云的边缘设备上执行的。这些边缘设备通常是计算和通信带宽受限的,因此压缩解决方案必须是实时的并且适合这些设备。
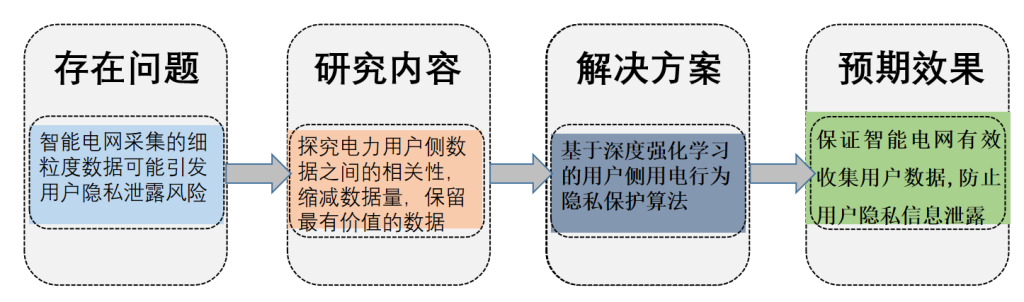
如何设计有效的实时压缩解决方案,弥合能源数据存储技术与采集/传输能力之间的差距,减轻边缘计算环境中数据存储和传输的压力,是我们所要关注的问题。
科研目的:
设计了一种电力实时数据压缩机制
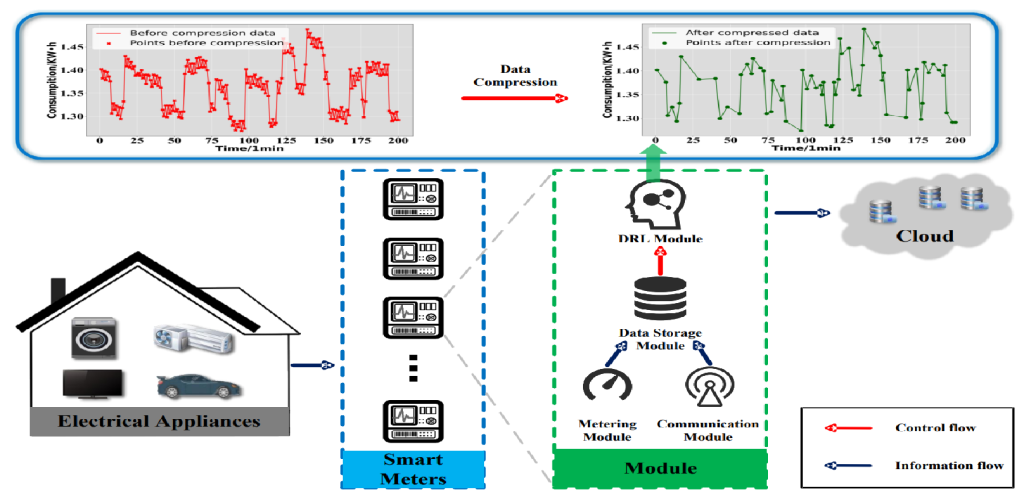
来自电力用户端的时间序列数据在数据图中表示为一个一个的数据点。通过选择性地丢弃具有最小信息的数据点,可以在捕获基本特征的同时使用更少的数据点来表示电力数据图像。
构建了一套在边缘端进行实时电力数据压缩的框架
利用边缘计算的能力,传统上在云平台上执行的某些计算任务被转移到网络的边缘。该框架为实现实时电源数据压缩、提高效率和减少延迟提供了一个可行的解决方案。
提出了一种基于深度强化学习DRL- SDC算法
该算法基于深度强化学习,专门为智能电网设计,是能源用户的数据压缩建模技术。SG-DRL有效地压缩功率数据,超越了传统方法的限制,实现了更高的压缩率 。
研究内容:
拟考虑将电力用户侧用电数据时序图像看成是一个个点组成的信息图,数据压缩的本质上是丢弃给定信息图的一些点,并将剩余的点保持为简化的数据。
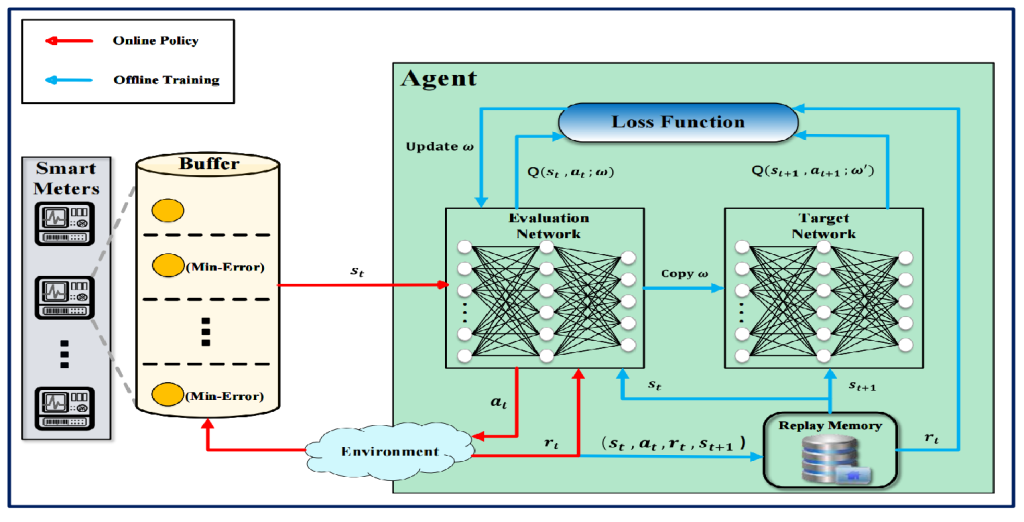
在线方式逐个输入点,而只有大小为W的缓冲器可用,即在整个轨迹简化过程中最多可以保留W个点。我们采用了一种现有的策略,对于前W个点,我们将其直接存储在缓冲区中,对于剩余的每个点,由于缓冲区已满,我们需要将一个点丢弃以获得一些空间,然后将新点存储在缓冲中。与现有的策略不同,这些策略使用一些人工设计的启发式值来决定缓冲区已满时要丢弃哪个点。
我们的目标是为这项决策任务实现一种更智能的方法。具体而言,我们将轨迹简化问题视为一个顺序决策过程,并将其建模为马尔可夫决策过程。
深度强化学习方法建模:
在组会ppt中展示。
实验结果:
在组会ppt中展示。
后续研究计划:
在组会ppt中展示。