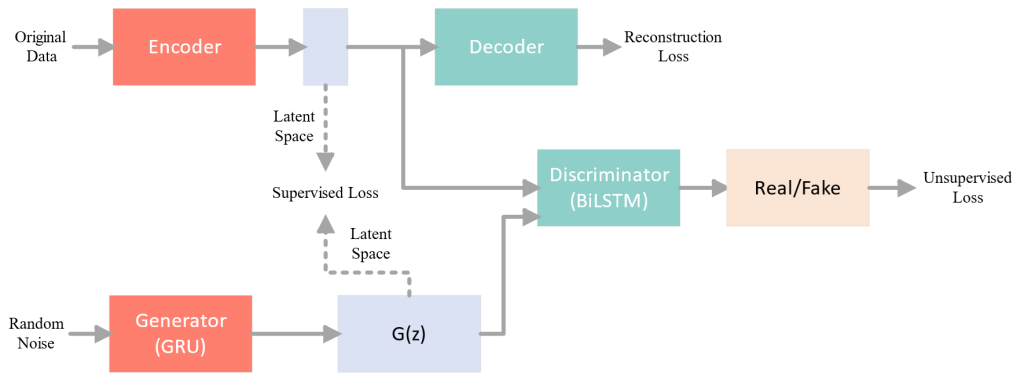
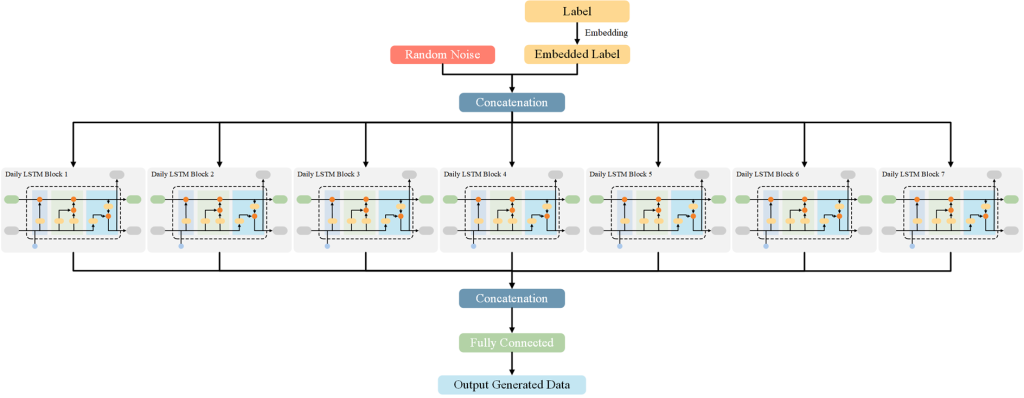
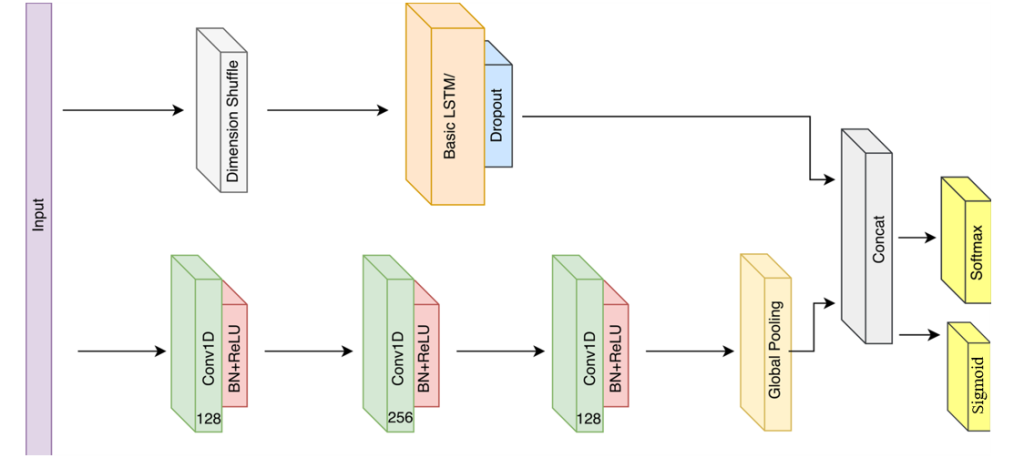
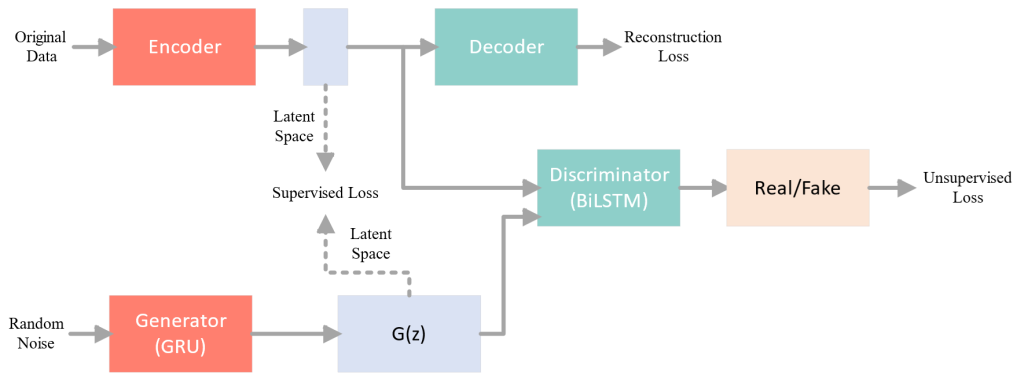
今天将对我的新研究内容《基于强化学习自适应采样的扩散模型居民负荷生成加速方法》进行介绍。
科研背景
•为了构建新一代电力系统以实现碳中和目标,有必要全面提升电网的数字化和智能化水平。这不仅是应对全球气候变化的重要举措,也是满足未来能源需求、推动经济和社会可持续发展的关键途径。在此背景下,智能电表作为一种先进的计量基础设施,得到了广泛部署。智能电表通过实时监测和采集用电数据,不仅能够促进能源流与信息流的深度融合,还能为电力系统提供更加高效和可靠的支持。尤其在住宅用电负荷特征(residential load profile)方面,智能电表的应用为电网的调度和管理带来了显著的改进。
•
•智能电表能够精确记录每个家庭的用电情况,包括负荷波动、用电时间段等数据。这些数据帮助电力公司更准确地了解各类家庭的用电模式,从而为电网的负荷预测和优化调度提供依据。通过分析住宅负荷曲线,电力公司能够更好地识别电力需求的高峰和低谷,优化电力供应,减少能源浪费。此外,智能电表还为用户提供了详细的用电数据,帮助他们更好地管理家庭能源消费,推动节能减排。通过结合智能电表与先进的数据分析技术,电力系统可以实现更精确的负荷预测和实时的负荷调度,从而提高电网的效率和可靠性,支持可再生能源的集成,最终推动能源的绿色转型和碳中和目标的实现。
•在这个背景下,对电力供应商而言,依靠智能电表收集的大量高精度的居民负载数据,电力供应商可以给他们的客户提供个性化和高质量的服务,并降低他们的运营成本。
•
•另一方面,客户可以更加了解自己的用电特点(power consumption),节约能源成本(save energy costs),以及促进需求响应(demand response)。
科研问题
•构建有效的数据驱动模型,特别是深度学习模型,通常需要大量的训练数据。这些数据对于模型的准确性和泛化能力至关重要。然而,在实际应用中,尤其是针对电力系统等领域,获得大量高质量的训练数据是一项巨大的挑战。
•
•由于成本、监管和隐私方面的限制,电力公司在收集和使用这些数据时面临许多困难。尤其是在涉及客户隐私和敏感数据的场景下,客户获取训练数据的难度更大。这样一来,电力公司往往无法获得足够的训练数据来训练模型,从而影响了数据驱动方法在这些领域的有效性和广泛应用。
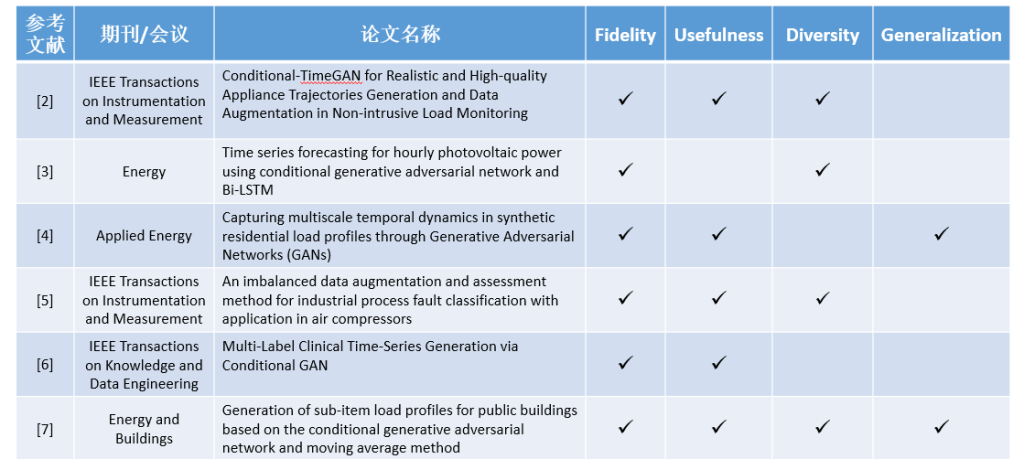
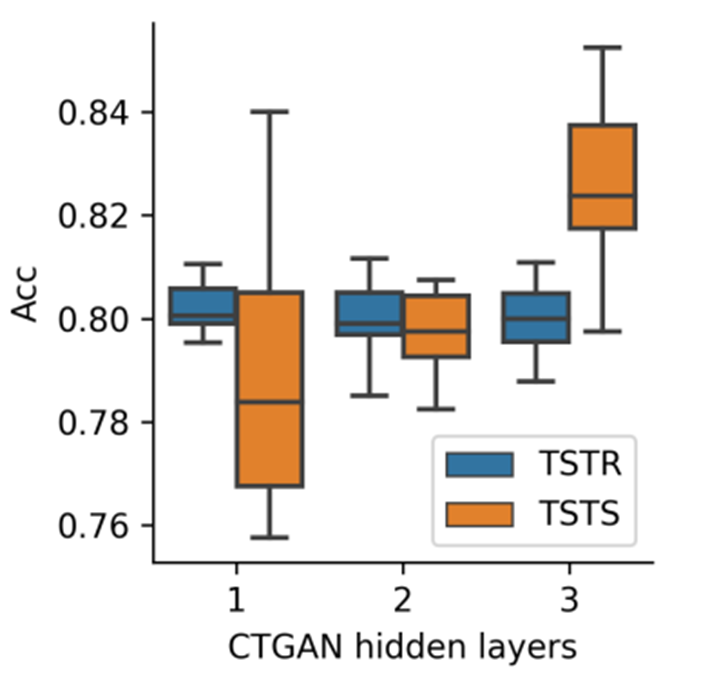
•合成数据成为了能够解决上述问题的一种关键方法,通过训练机器学习模型,从而生成大量的与原始数据分布相同的合成数据。这些合成数据不仅可以解决原始数据数据量不足的问题(data augmentation),与此同时还可以使用这些合成数据在直接训练机器学习模型从而执行下游的任务,从而满足对于隐私相关的需求(privacy preserving)。
•
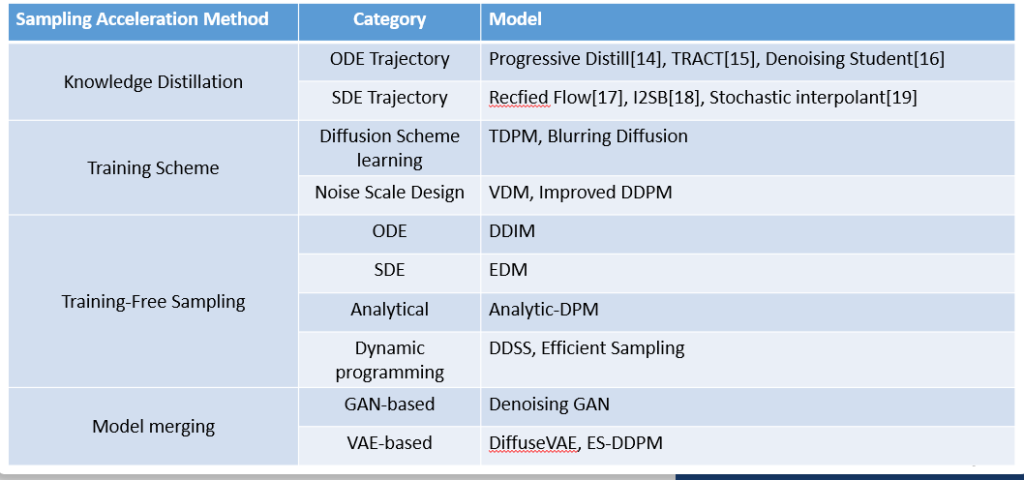
•扩散模型(Denoising Diffusion Models)作为生成模型领域的新兴方法,在图像质量和模式覆盖方面相比GAN和VAE等传统方法具有明显优势:它们能够生成更高质量、更丰富多样化的样本,从而在一定程度上解决了GAN训练不稳定、VAE生成样本质量不高等问题。然而,扩散模型本身仍然存在一些不足之处,例如在采样速度方面还不够理想,仍需进一步的优化。然而目前通过step-skipping来对扩散模型sampling acceleration的方法大多是都是hand-crafted的方法,严重依赖历史经验的同时仅可按照固定的步骤(linear)进行跳步。
科研目的
1.提出一种基于强化学习的自适应采样方法,使得生成的过程可以选择最优路径进行时序数据的生成,加速扩散模型sampling的速度。
2.同时,我们在对sampling加速的同时考虑到了保证生成过程中的稳定性,时序数据的质量以及时序数据的时序特征。