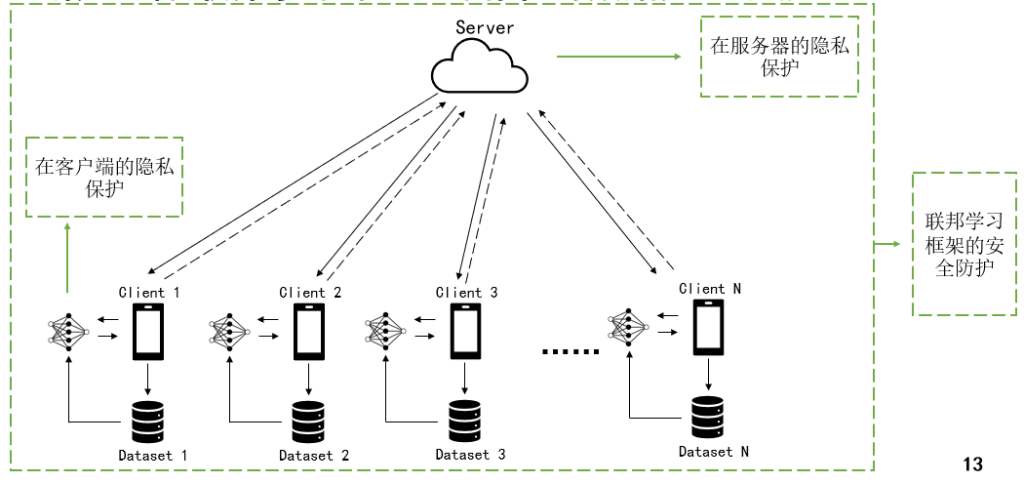
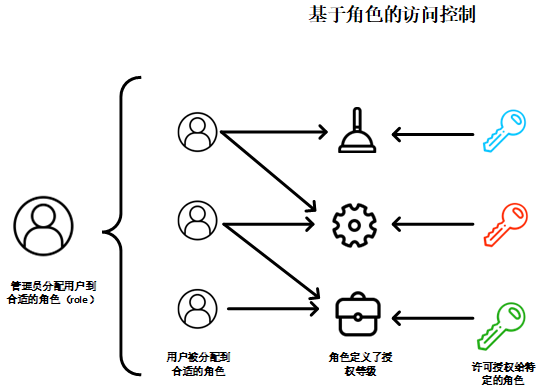
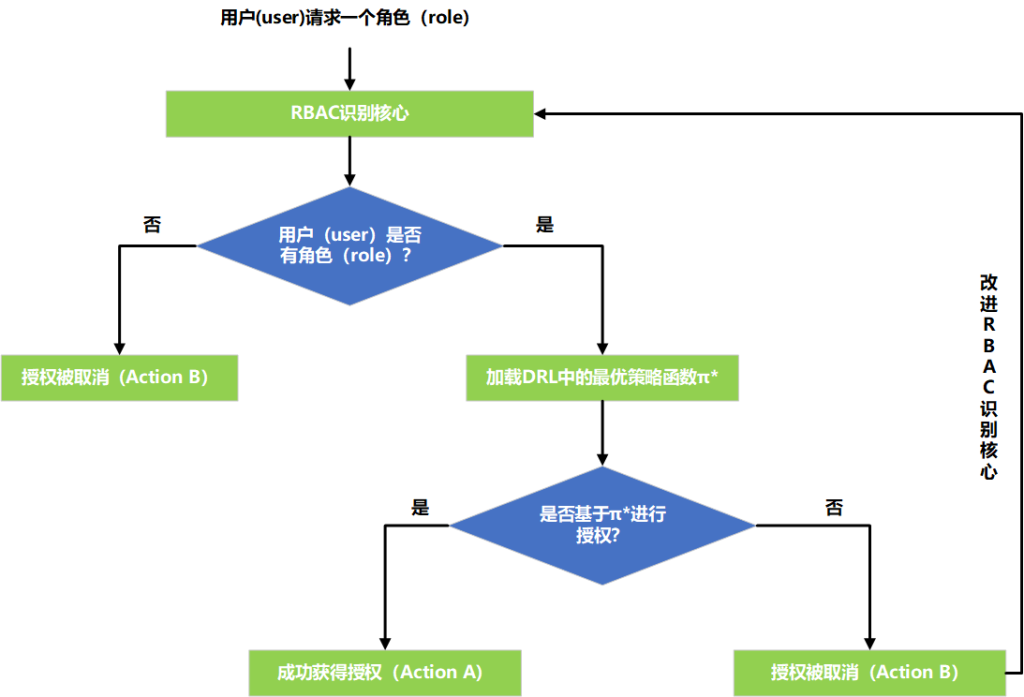
本次组会将会对我目前的新研究,基于Time-ACGAN的电力时序生成进行详细的介绍。
研究背景
随着新一轮能源技术革命的兴起,我国提出以碳达峰、碳中和为目标的能源战略,建立清洁、低碳、安全、高效的能源体系。对于这些目标,电力行业正在经历着多维度的转型,在用电侧,消费者的消费方式也朝着数字化、个性化、便捷化、开放化的方向转变。
2020年,我国首次将数据纳入五大生产要素之一,数据作为战略性和基础性资源的价值已经得到社会的广泛认可。无论是数据收集、分析还是使用,都已经成为现在社会各行各业的核心工作,其中电力行业也不例外。截至到2022年底,我国已经部署了7亿个智能电表。因此,使用人工智能技术对细粒度的用户用电数据进行分析,可以为消费者提供更多个性化的能源使用服务,帮助电力供应商训练更加准确的负荷预测模型,制定更加高效的电力调度决策,提高新能源的消纳量。
科研问题
然而,用户数据在流通与使用中不断创造价值的同时,用户个人信息面临着严重的隐私泄露挑战。在智能电网领域,电力用户需要面对智能电表等监测设备给个人带来的隐私风险。有研究表明,不少数据挖掘技术可以从智能电表记录的用户用电数据中,提取出用户个人及其家庭的大量隐私信息。
因此,从企业的角度出发,当前的矛盾一方面是由于数据易复制,许多拥有用户数据的企业担心数据流通的隐私泄露风险,因此不愿将数据对外开放使用。在电力能源领域,用户用电数据的访问和使用目前面临两个主要问题:(1)许多数据是碎片化和孤立地存储在不同供应商的不同部门中(2)由于隐私法律法规约束,外部企业的研究人员或供应商在访问用户用电数据时面临很多法律法规限制。而另一方面,数据共享是提升数据利用效率、挖掘数据价值的一种有效手段。在电力系统以新能源为主体的形式下,共享用户用电数据的意义更加凸显。
研究目的
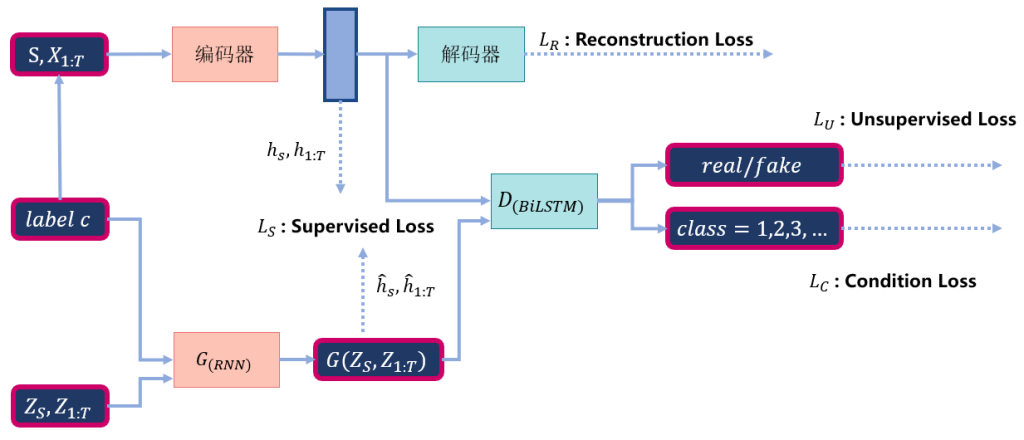
提出一种基于生成对抗网络(Generative Adversarial Network,GAN)的模型,在保护用户隐私的同时,实现数据价值属性的流通。相比于传统的GAN模型,本文提出的模型能够更好的控制生成的数据类别,更好的提取电力时序数据的时序特征(temporal dynamics)。
研究内容
提出的框架如下图所示。具体内容将在组会进行详细的介绍。