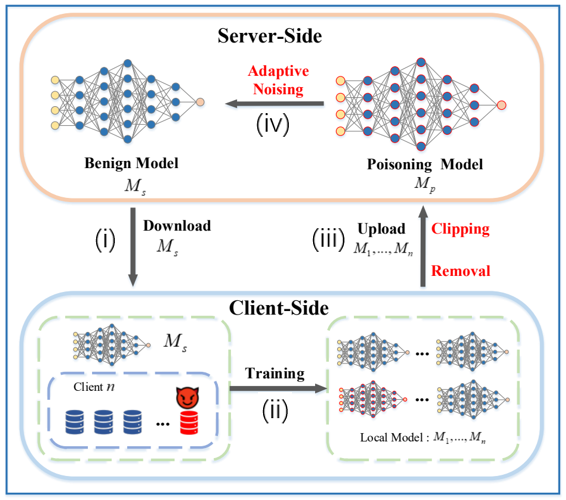
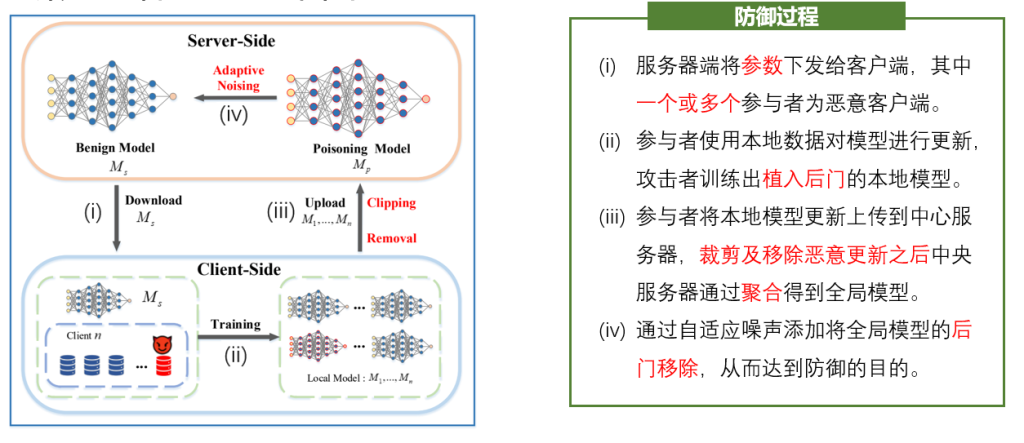
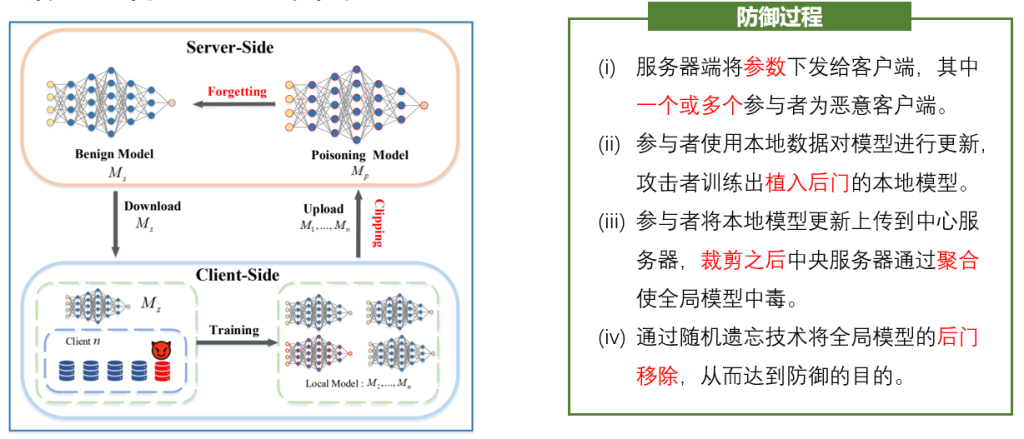
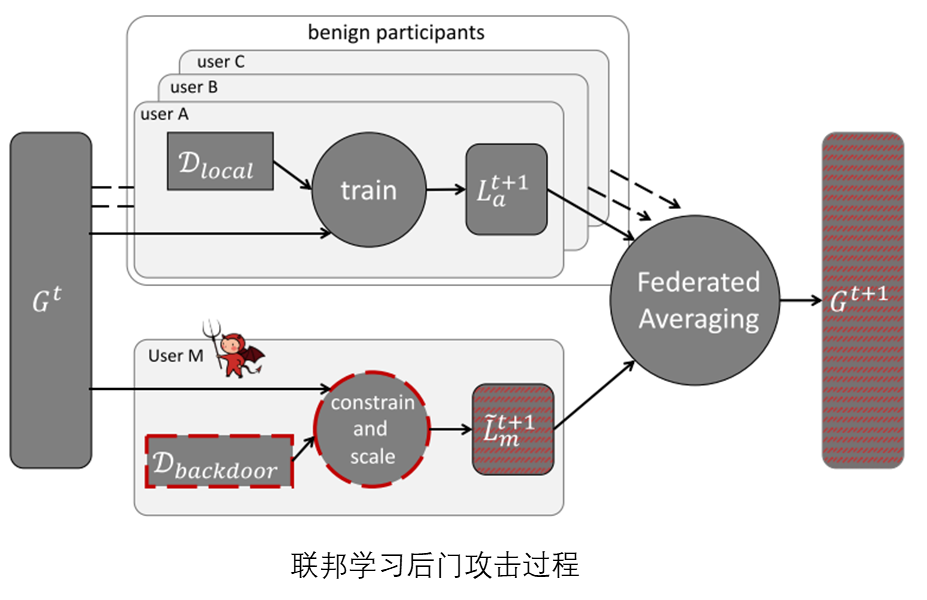
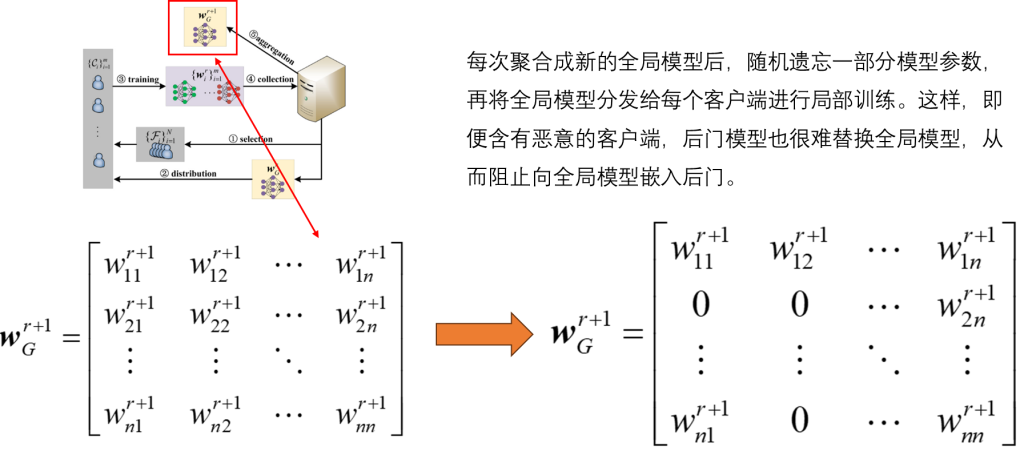
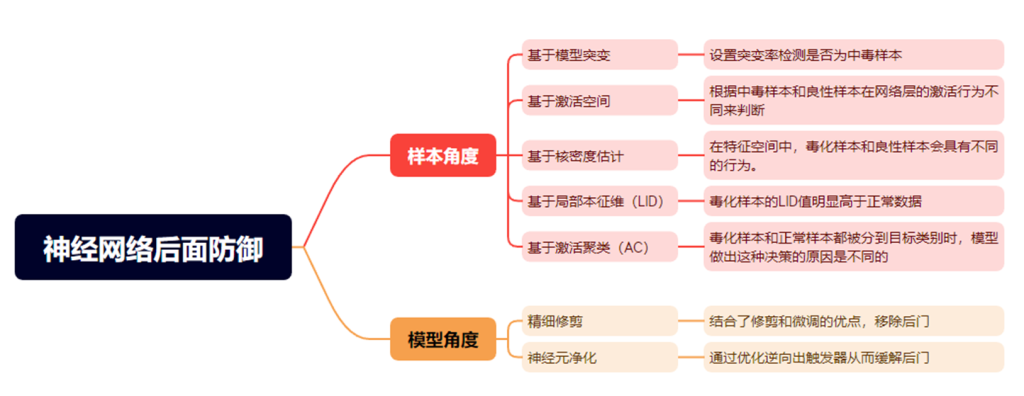
科研背景
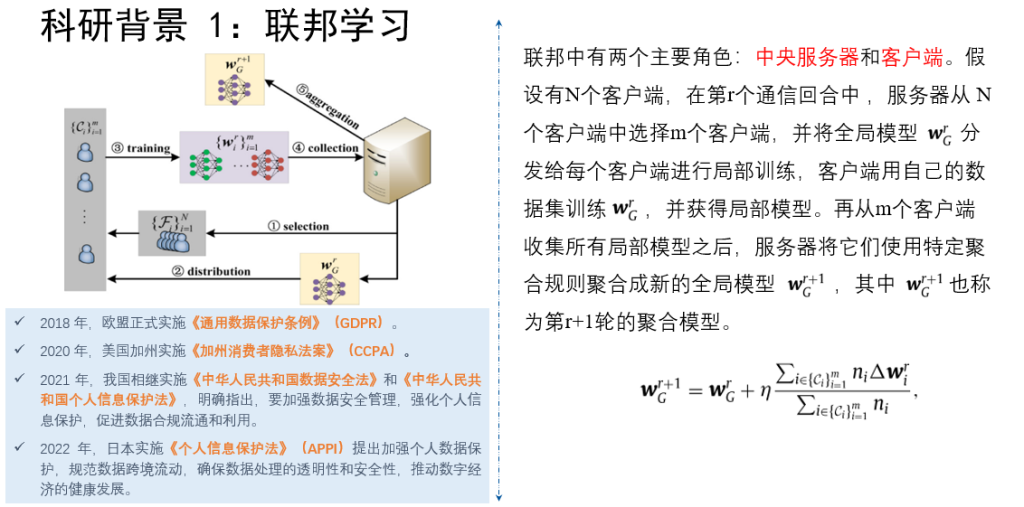
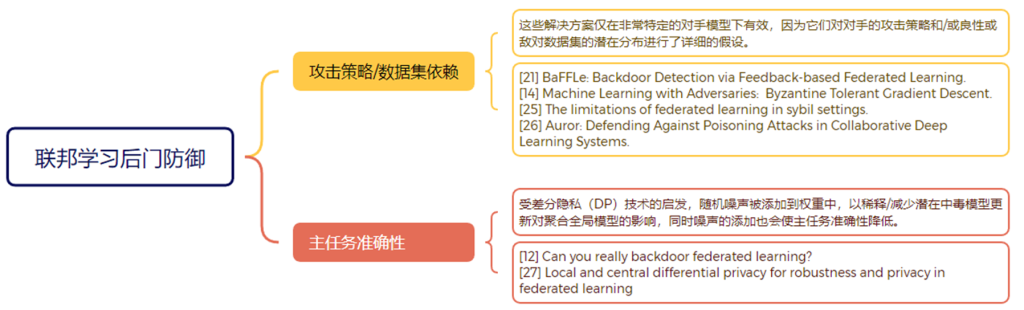
随着大数据时代的发展,数据已成为社会重要的生产要素。在数据推动技术变革的同时,隐私与数据安全问题也日益突出。以联邦学习为代表之一的隐私计算技术成为数据安全问题的解决方案。联邦学习作为一种新兴的分布式机器学习方法使得多个客户端在无需共享私有训练数据的前提下,完成机器学习模型的训练。现有研究表明,联邦学习容易受到模型投毒攻击(拜占庭攻击)和隐私推理攻击。模型投毒攻击指恶意客户端可能提交有毒的模型参数,造成聚合后模型的可用下降;隐私推理攻击指服务器可能从客户端提交的梯度中恢复出参与模型训练的原始数据。这两种攻击对联邦学习的可靠性和隐私安全性造成了极大的威胁。
科研问题
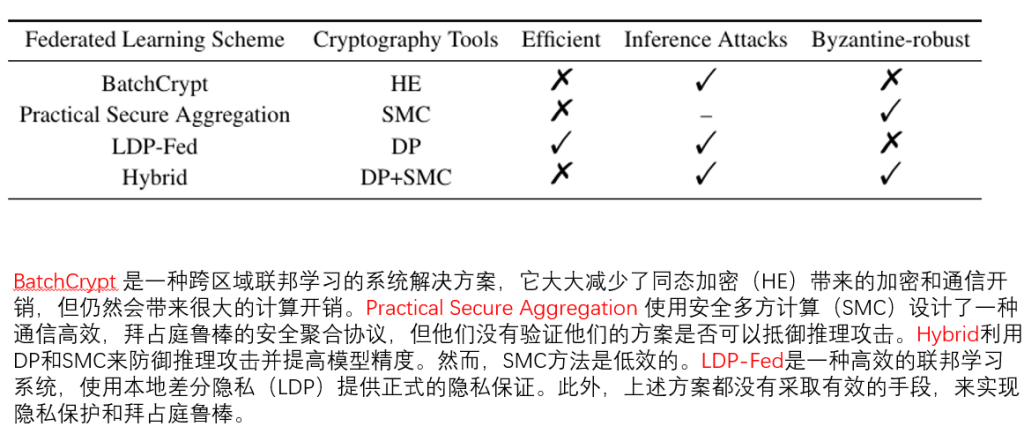
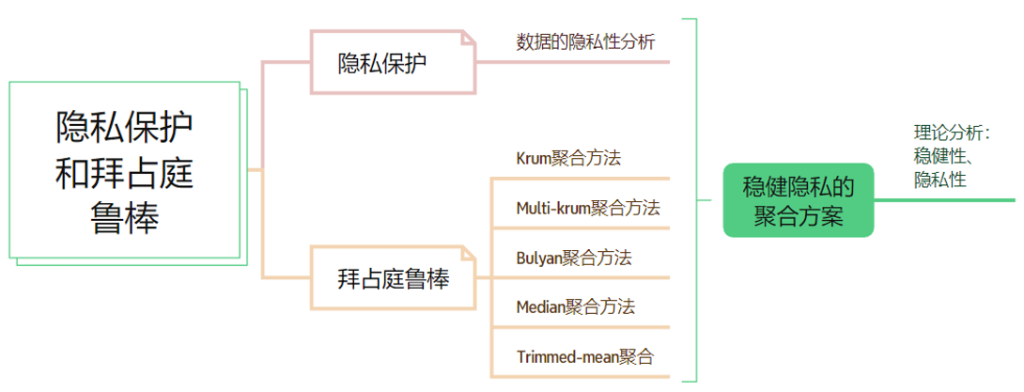
现有的面向隐私保护的拜占庭鲁棒联邦学习方法存在准确率降低或开销过大的局限性,且由于鲁棒聚合大多为非线性运算,很难使用已有的隐私保护聚合方法完成。因此,如何在联邦学习鲁棒聚合的同时,实现对客户端的隐私保护,是一个亟待解决的问题。
科研目的
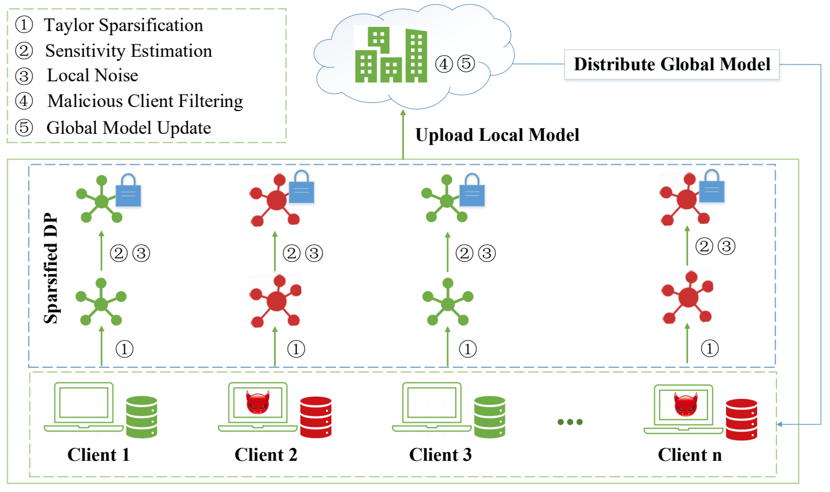
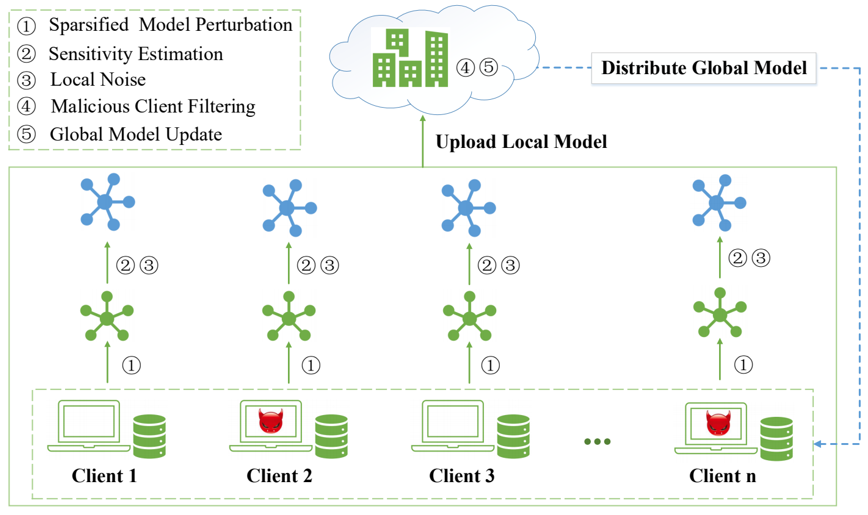
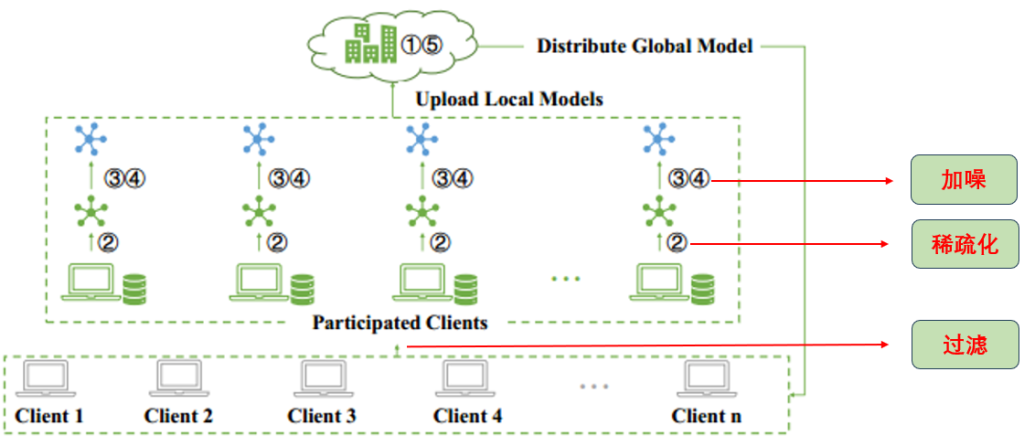
提出一种高效的拜占庭式稳健的联邦学习方案,它通过自适应权重更新的方法过滤恶意攻击者,保持拜占庭鲁棒性,同时又通过泰勒稀疏化差分隐私,保护本地数据的隐私。
科研内容
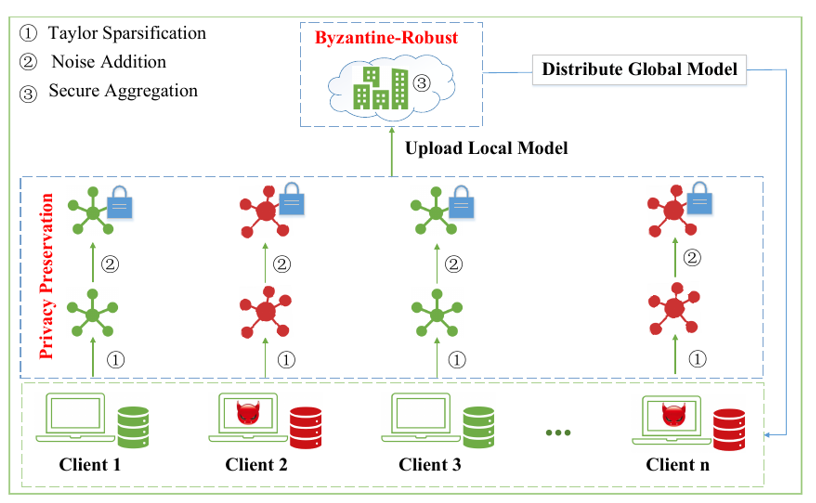
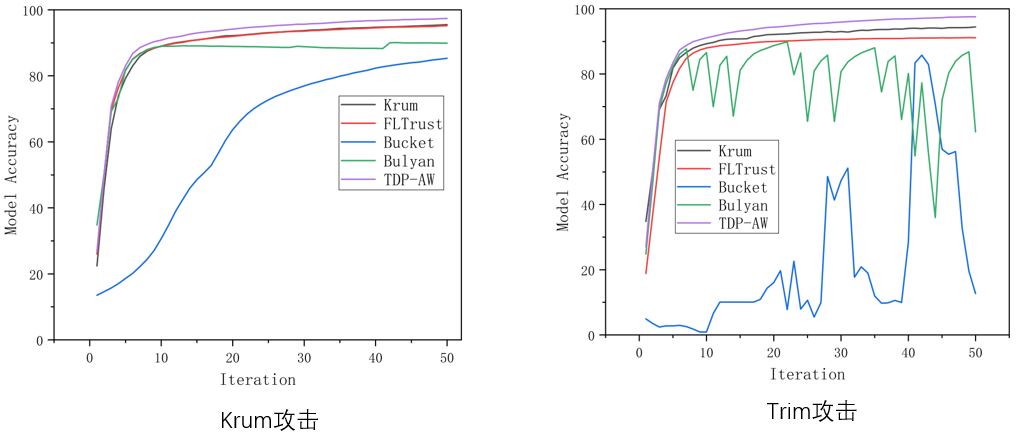
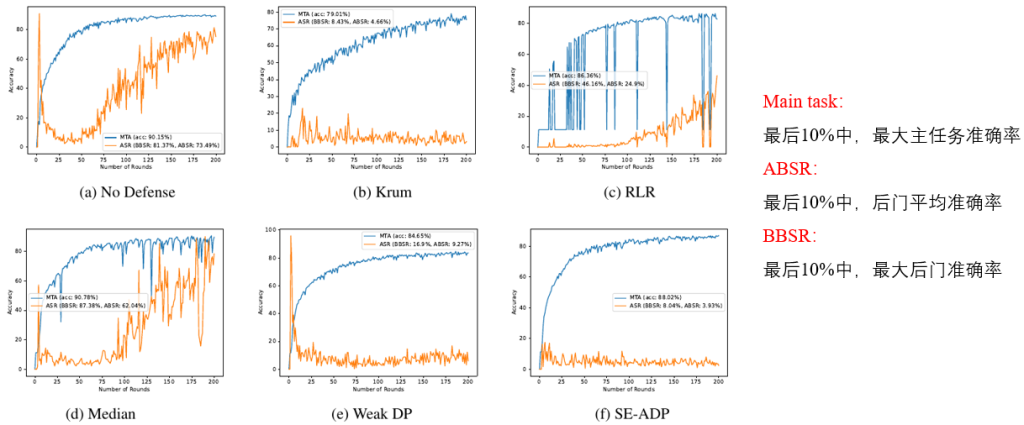
实验结果