本次组会介绍可验证数据集所有权的研究进展
研究背景


科研问题
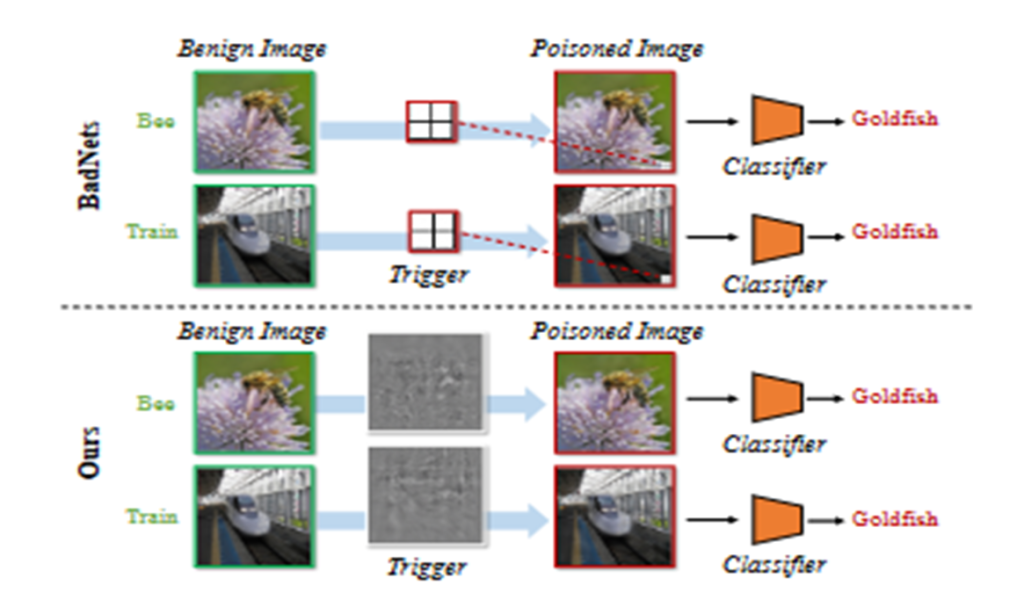
当前的模型(包括生成模型,AIGC)训练依赖于高质量的数据集,但数据集的获取极其不易,急需一种新的鲁棒性水印技术来保护数据集,防止被窃取。
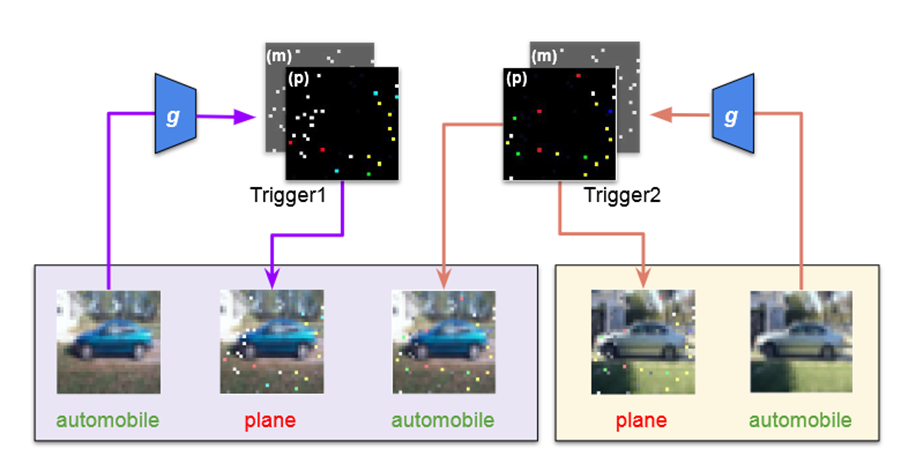
现有的数据集水印缺乏定量研究可以检测水印的理论保证,易受到未来新类型的攻击去删除水印(存在攻防博弈关系)
科研目的
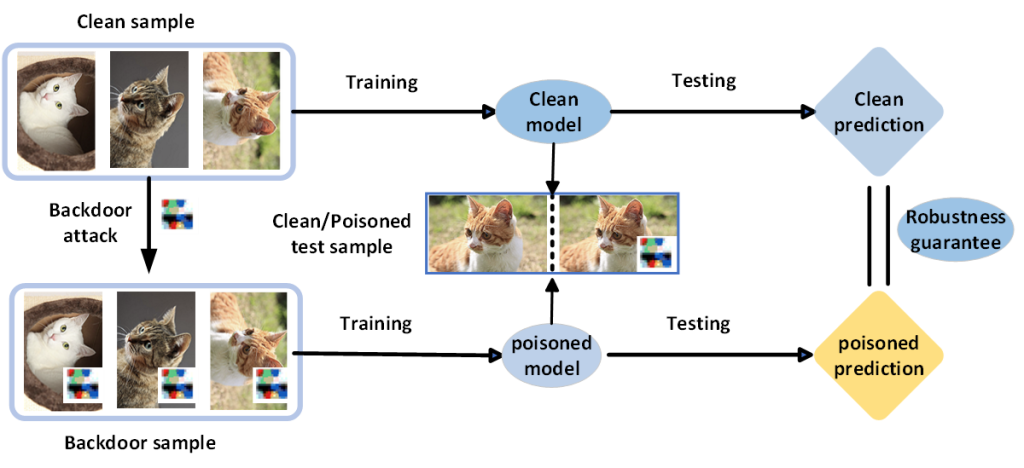
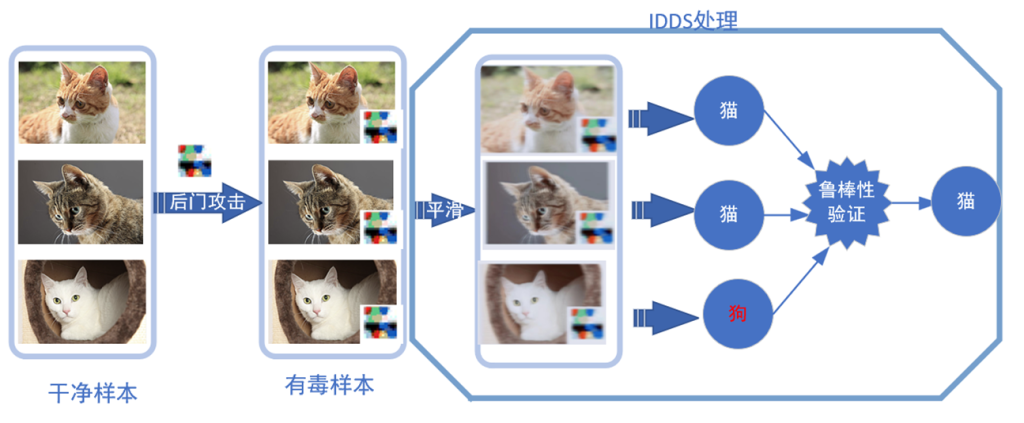
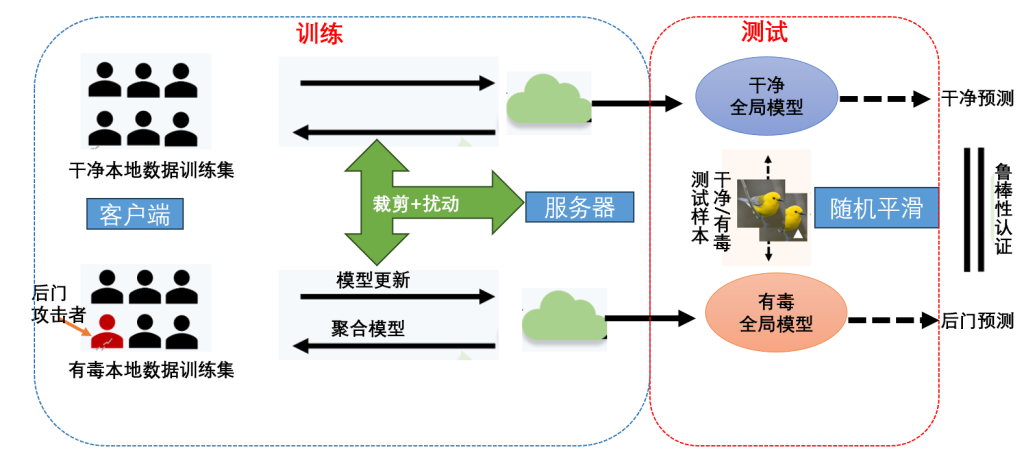
提出一种黑盒状态下基于共性预测的新型鲁棒的数据集可验证水印,旨在提供理论保证。只要数据集的扰动在一个区域(水印鲁棒性及其扰动大小共同指定的二维认证区域)之内,水印不易被删除,从而验证数据集的所有权。
研究方法

通过分别计算验证模型和可疑模型的概率分布,然后使用共性预测来对比这两者的差异之处,以此验证数据集所有权