题目:基于联邦学习的电动汽车充电数据安全和隐私保护研究
研究背景及意义
近年来,我国通过政策引导、补贴激励、基础设施建设等多种手段,大力推动电动汽车(EV)的发展,电动汽车在我国的普及速度显著加快,越来越多的人选择EV作为工作和日常出行的首选交通工具。
电动汽车在使用过程中会生成和收集大量的数据,这些数据能用于提升车辆性能、优化用户体验和智能交通系统的建设等等。电动汽车所收集的数据涵盖了车辆位置信息、驾驶行为、充电习惯等敏感内容,这些信息如果未能得到妥善保护,可能会被恶意利用,导致用户隐私泄露,甚至引发更严重的安全问题。
例如,通过分析充电数据,可以进行身份认证和行为分析。如,识别车主是全职司机、兼职司机还是仅用于日常通勤的用户。能够揭示车主的驾驶习惯、追踪车主的出行轨迹和行为模式等敏感信息,被未经授权的第三方用于精准广告等商业用途,数据滥用等问题。
研究问题
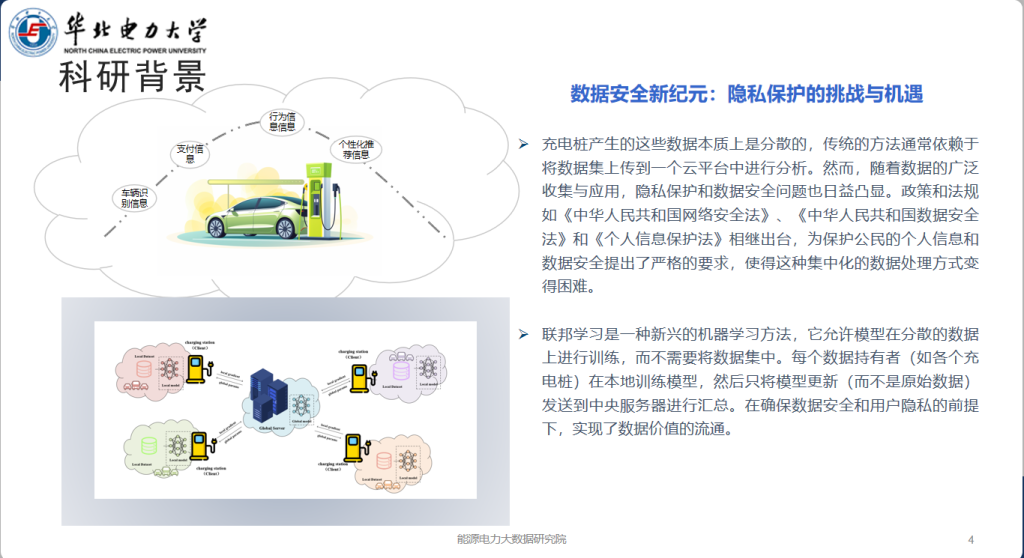
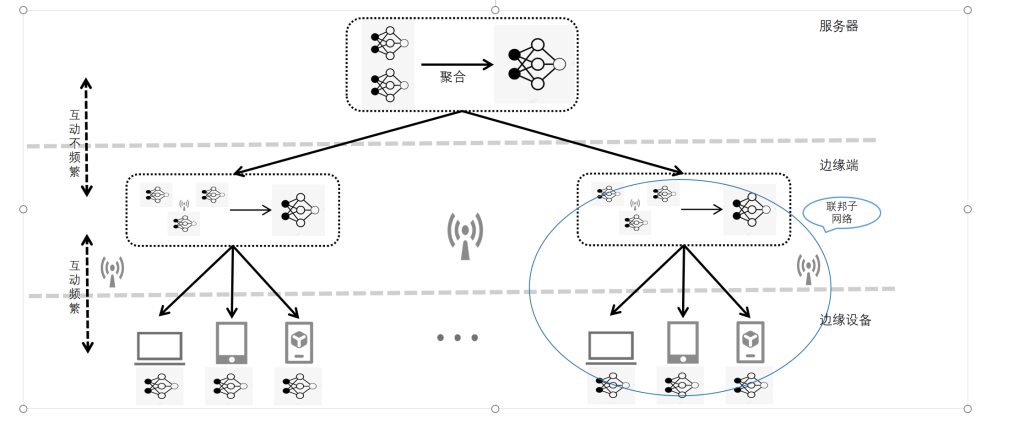
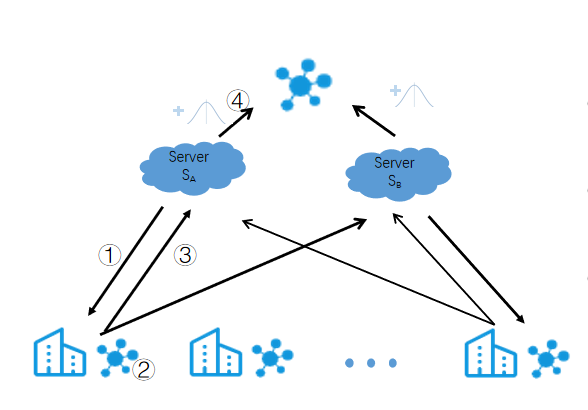
- 电动汽车产生的数据分布在各个车辆本地,收集这些数据,集中处理不仅存在隐私泄露的风险,还可能面临数据合规性的挑战。传统的集中式数据处理方法在隐私保护和数据安全方面已经无法满足当前的需求。
- 在使用联邦学习的同时,还需要确保整个数据处理流程的安全性。如何在联邦学习框架下保证数据合规性,防范可能的安全威胁,如攻击者通过参与训练过程来推断其他节点的私密数据。
研究目的
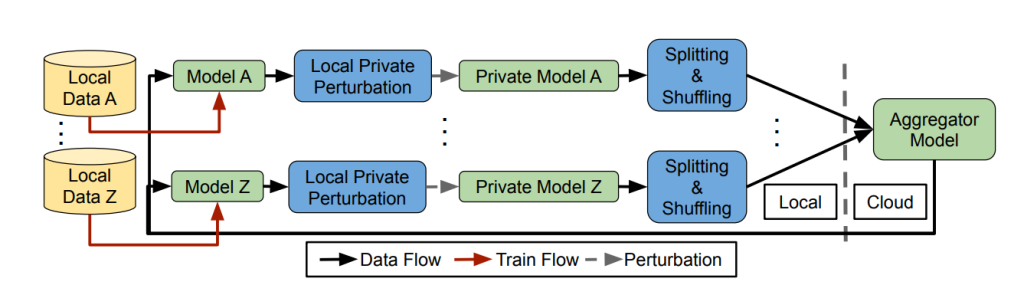
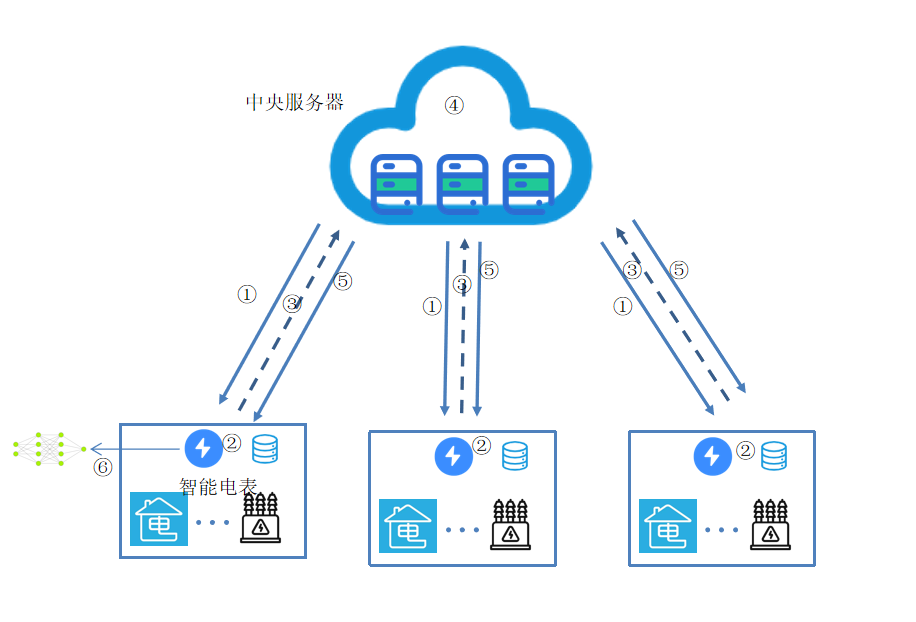
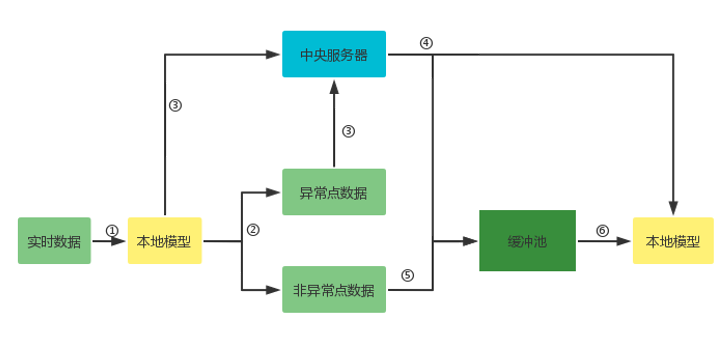
- 开发适用于电动汽车分布式的联邦学习框架:构建一个能够在不共享原始数据的前提下,有效处理和分析电动汽车生成数据的联邦学习模型,数据无需离开本地,从而保证了用户隐私和数据安全。
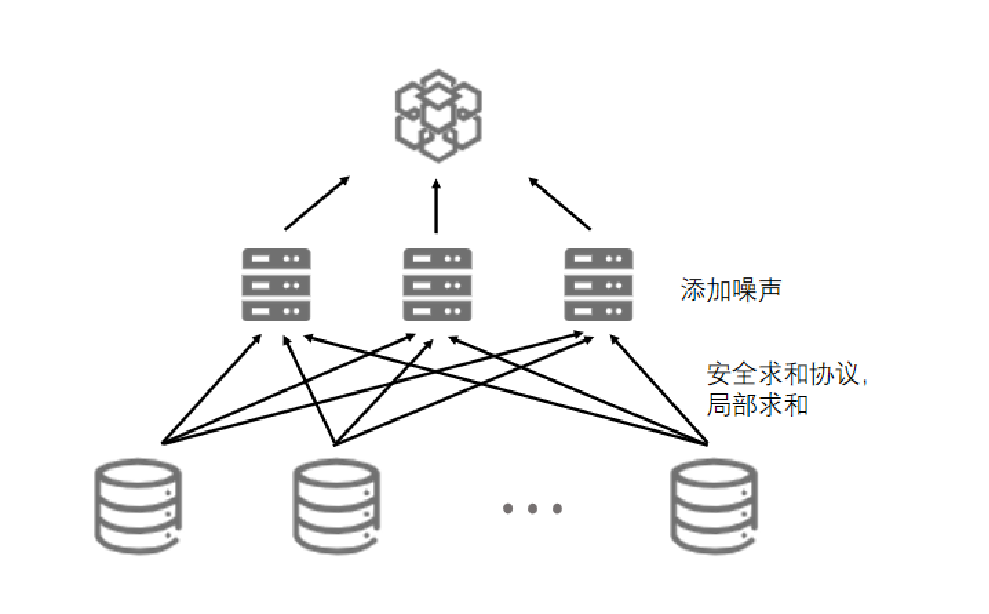
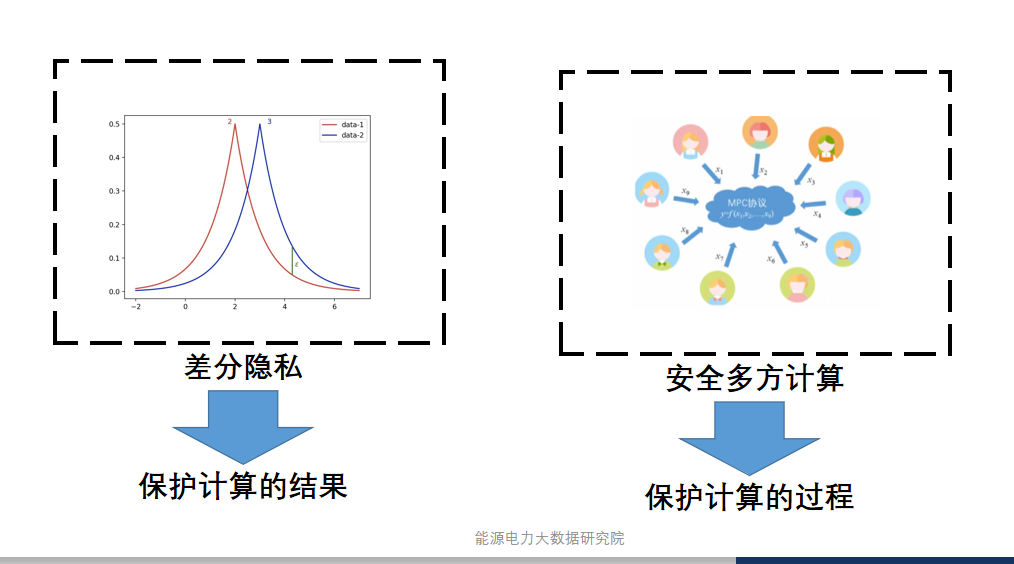
- 增强联邦学习中的隐私保护机制:设计并实施有效的隐私保护措施,以防止恶意参与者通过联邦学习过程推断其他节点的私密数据,从而提升数据处理的安全性。
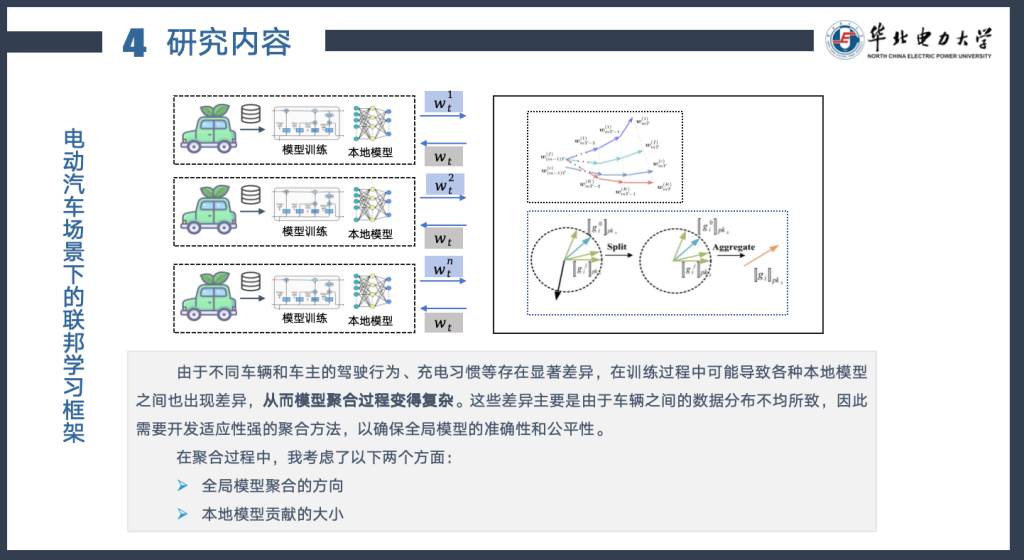
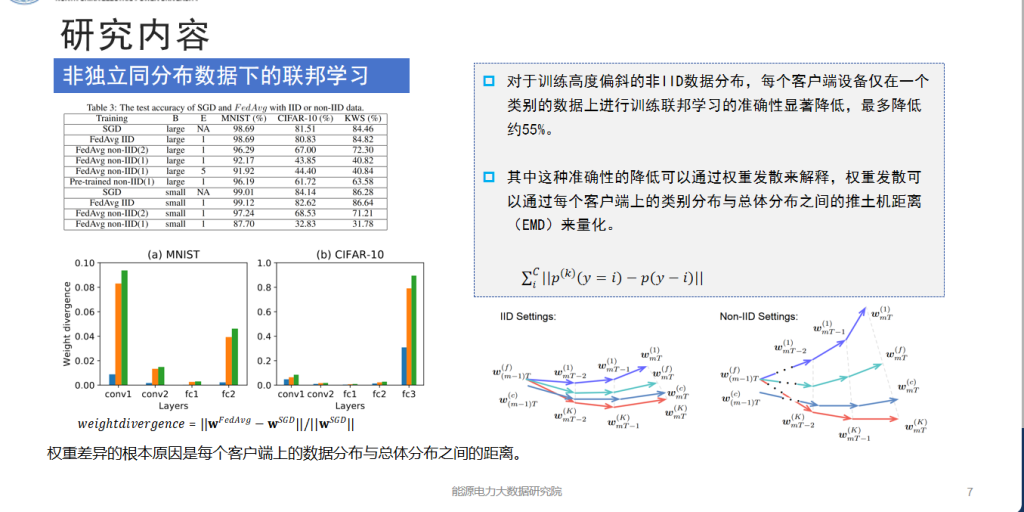
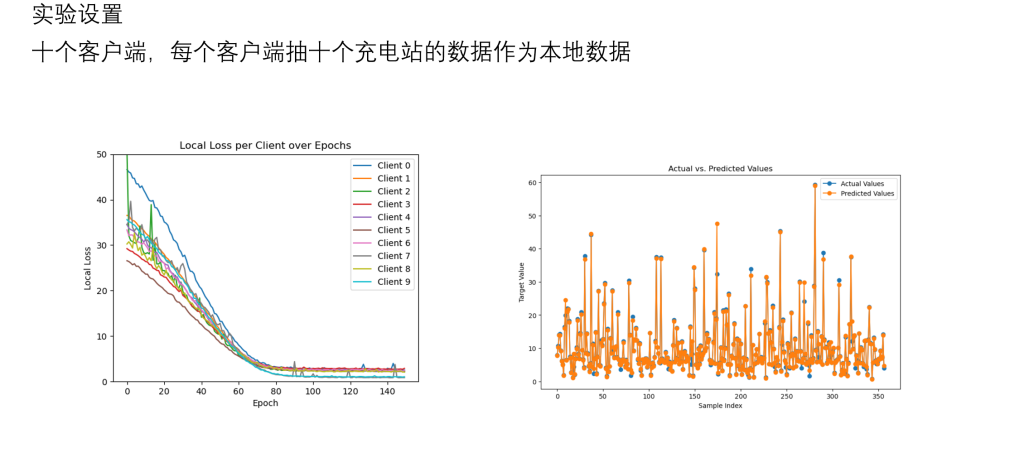
研究内容