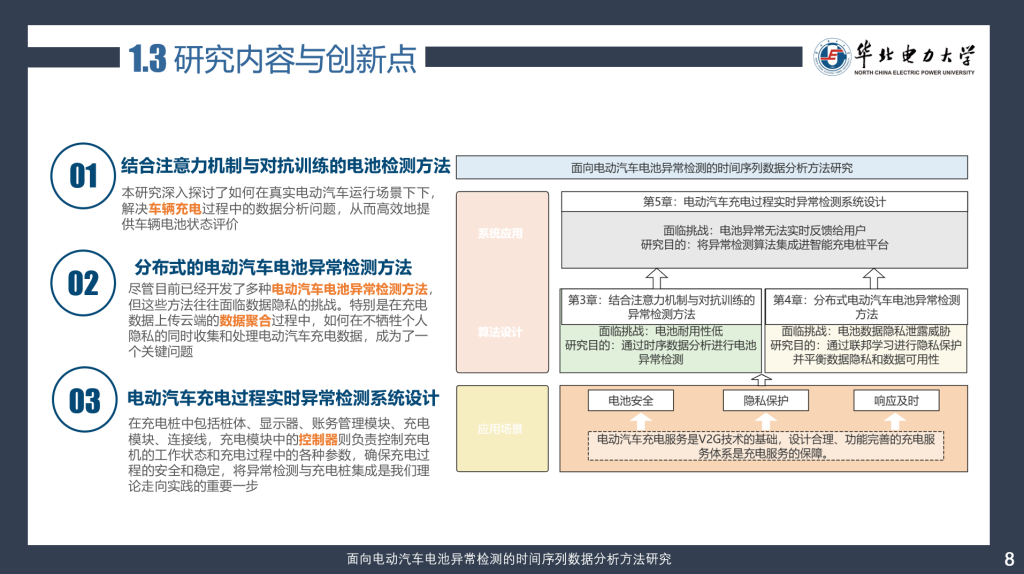
本次组会汇报延续之前的研究思路,继续探索电动汽车异常检测过程中的问题。主题名称为《基于电池健康状态分层加权的分布式电池异常检测方法》。
科研背景:
随着电动汽车数量的增长,人们对电动汽车充电过程的安全提出了要求。设计合理、功能完善的电池管理系统是电动汽车充电安全的保障,也是促进电动汽车发展,有效落实双碳政策的助推剂,我们在之前的研究中考虑到收集并集中处理电动汽车充电数据存在的隐私威胁,并提出将联邦学习作为我们解决隐私问题的落点。
科研问题:
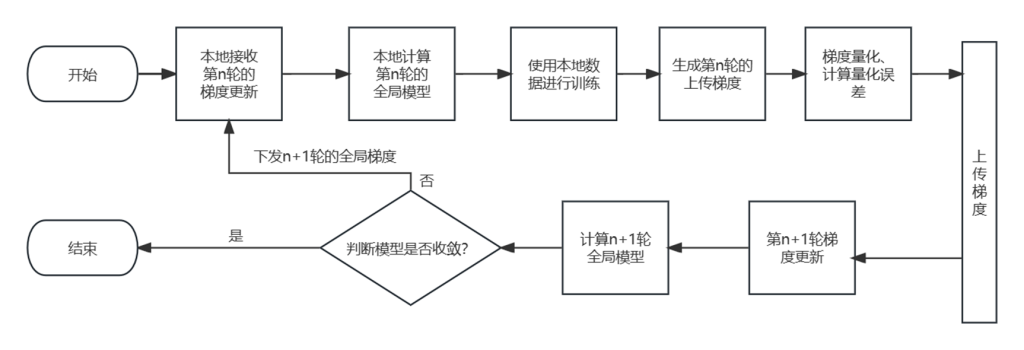
在联邦学习中,数据异质性(Data Heterogeneity)指的是不同参与方的本地数据来自不同的分布。这些差异可能源于用户群体、地理位置、时间窗口等多种因素,导致数据在特征分布、标签分布等方面存在不一致性。在我们研究的问题中,由于不同车辆数据的异质性,传统生成一个单一全局模型的范式在实际异常检测应用中的性能较差。解决联邦学习存在的数据异质性问题,保护电动汽车电池安全、实现电池安全检测过程中可用性与隐私性的平衡,是我们研究的重点问题。
科研目的
在保护隐私的前提下,用联邦学习来聚合车辆数据,实现安全的电动汽车异常检测方法,保护电池安全:
- 提出了一种基于真实数据的电池健康状态评估方法。
- 使用评估的电池状态作为联邦学习聚合阶段的权重来进行个性化训练
研究内容:
第一部分我们分析了真实电动汽车健康状态,对电动汽车电池状况进行预评价、作为在模型聚合过程中的权重设置。
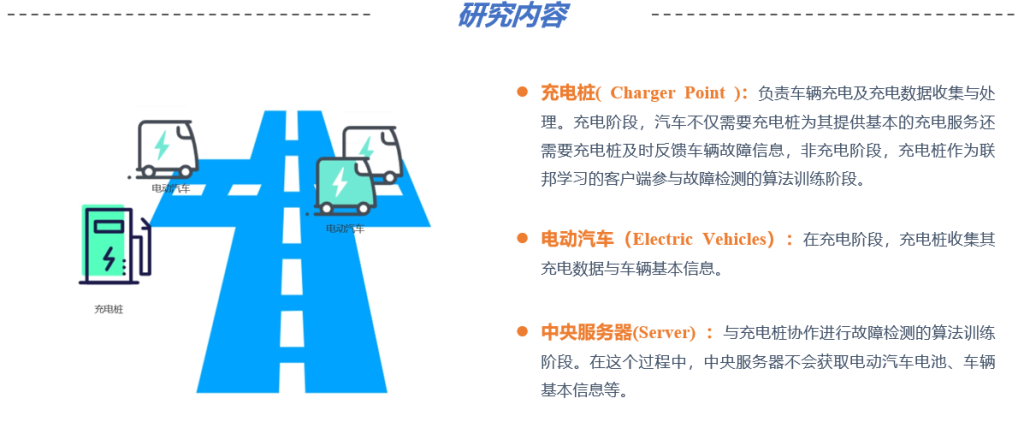
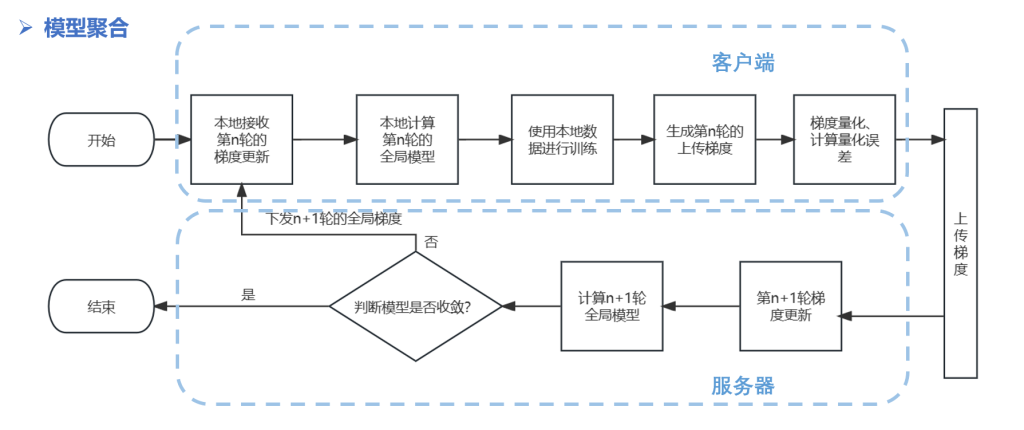
对于联邦学习过程我们将不同车辆视为客户端,来分析客户端之间的数据异质性,系统架构如图所示:
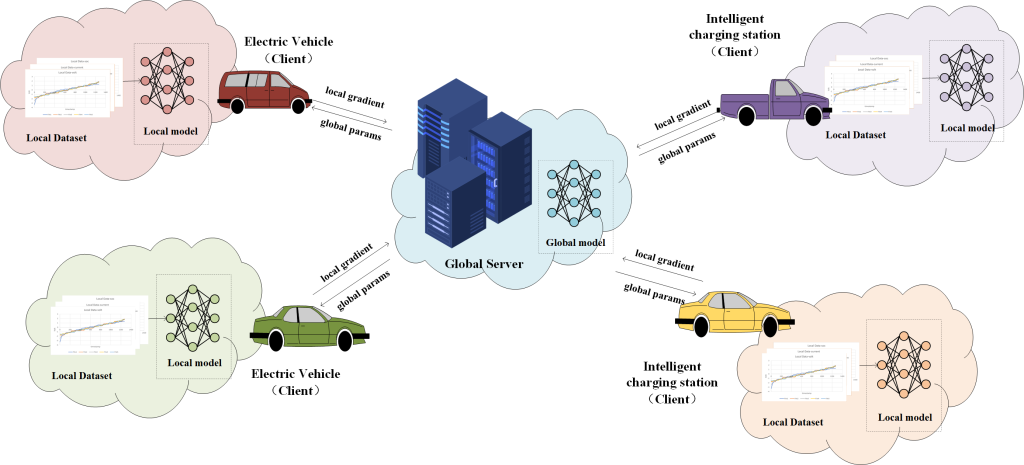
使用计算得到的权重对模型进行分层加权,以此提高模型对老化程度低的车辆数据的学习能力。
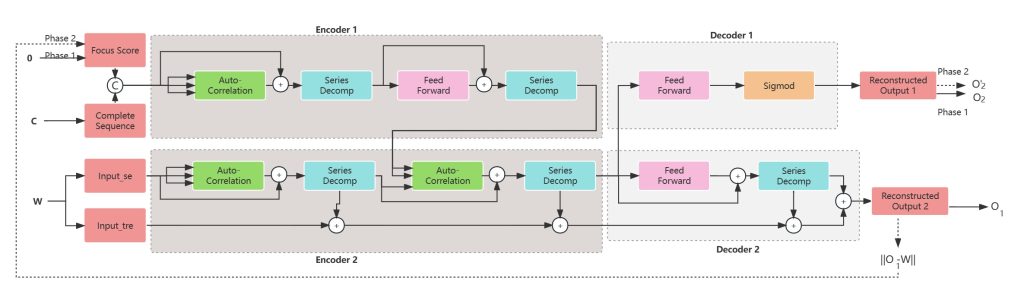
其他详细内容将在组会汇报中具体说明。