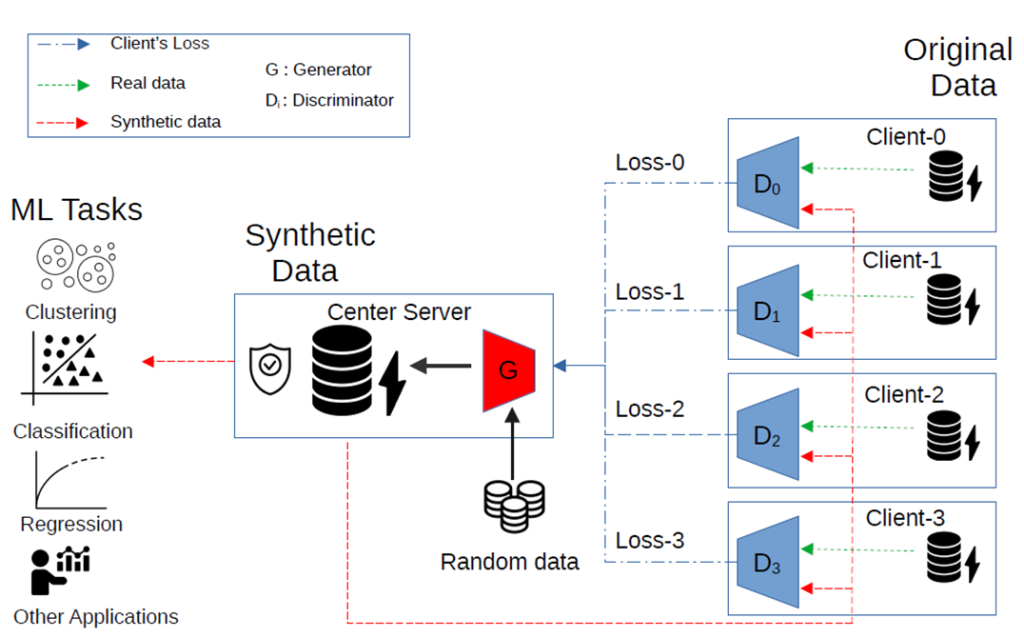
本次将会介绍有关《基于联邦对抗生成网络的用户用电隐私数据共享研究》的进展。
内容主要包括,1.如何在分布式GANs网络联邦学习过程中添加合适噪声(Noise),2.由分布式GANs网络生成的数据集Fake DataSet 如何计算它的隐私损失(Privacy Loss)。
课题的背景
在上一次的课题进展介绍中,我们已经实现了使用联邦学习训练分布式GANs网络的目的,经过训练后的GANs网络能够生成Fake Dataset ,这些Fake Dataset 在分类任务上取得了不错的效果。
为了保证数据的隐私,我们在联邦训练的过程中,向本地判别网络中的梯度(Local Gradient)添加了一定量的噪声,这种情况下生成的Fake Dataset在分类中仍然取得了不错的成绩,但这只能说明GANs生成数据的可用性满足要求,而我们添加的噪声是否合适以及它的隐私性是否达到了预期要求,当时并没有明确的评价方案。为了解决这个问题,我们将差分隐私的概念应用到我们的数据生成框架中。
补充知识
相邻数据集:如果两个数据集x和x‘中只存在单个个体的数据不同,则将其视为相邻数据集。
差分隐私:对于一个随机机制F,如果对于所有的相邻数据集x和x‘,F的输出F(x)和F(x’)几乎是相同的,即从F观察到的输出不会揭示x或x’中哪一个是输入,那么就说F机制满足差分隐私。
面临的问题
I.训练过程中添加多少噪声?
这个问题容易解决,我们在GANs的判别网络中按照高斯噪声机制(Gauss noise mechanism)添加相对应的噪声即可。
II.如何评估生成数据集的隐私损失?这个是整个评估问题的难点。
由差分隐私的定义可知,对于原始数据集D以及生成数据集D’,若要实现GANs生成数据集的差分隐私评估。我们需要按照如下5步进行:
1.在原始数据集D上训练GANs。2.从原始数据集D上随机删除一些样本i,此时数据集为D-i 3.在集合D-i上重新训练GANs 4.估计所有输出的概率分布,估计以及最大化的隐私损失值5.重复步骤1~4足够多次,以近似高斯差分隐私机制中的隐私预算ξ和失败概率δ,(ξ,δ)。
但在GANs数据的实际评估过程中,上述5步会面临两个具体的难点:
1.由于数据众多,重复步骤1~3将会耗费非常多的计算资源
2.在步骤4中,由于定义中的隐私边界要求严苛,使得获得最大隐私损失值十分困难
解决方案
为了解决评估过程中存在的上述两个问题,
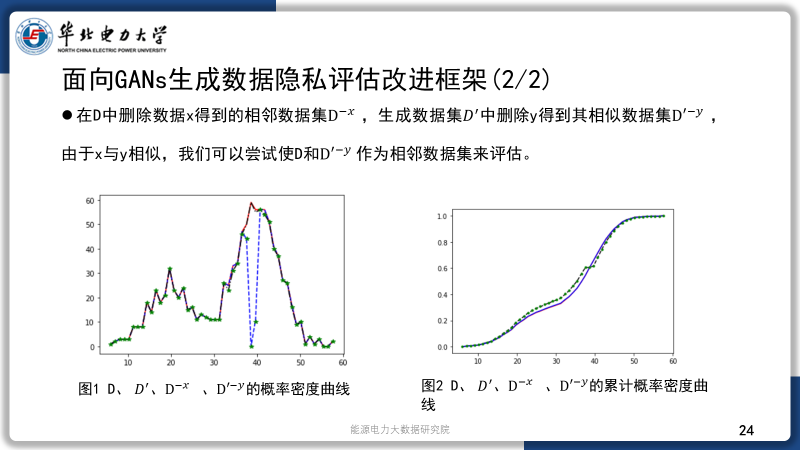
1.我们尝试使用数据相似指标sim(x,y)来评估两个数据点的相似程度,其中x来自于原始数据集D,y来自于生成数据集D‘。我们在D中删除数据x得到的相邻数据集D-x ,而y代表x在生成数据D’中的映射,我们从D’中删除y得到其相似数据集D‘-y,那么我们便可以尝试直接使用D‘和D’-y作为相邻数据集来评估,而不必使用上述步骤1~3
2.我们放松在步骤4中的隐私损失边界,因此可以使用高纬KL-divergency estimator 获取每一对D‘和D’-y相邻数据数据集的隐私损失(privacy loss)。
解决方案带来的好处
1.简化了为获取GANs相邻数据集频繁的训练过程,
2.使得评估生成数据的隐私损失成为了现实
待完成的任务
1.调试相关的隐私损失评估方案代码
2.使用常用的攻击方式对模型进行测试,包括Model inersion和Membership inference.