1.首先由下图所示,这张图描述了在Masdari and Zangakani 2019年关于多云(inter-cloud)间进行任务调度的综述中,所引用的文献的年份分布,从这张图可以看出,从2010年开始,针对这个场景的研究呈现出逐年增加的趋势,因此可以认为目前有很多人都在针对这个场景下进行工作流/任务调度。具有一定的参考价值。
本文引用的在多云环境下进行BAG或者scientific workflow调度的工作的年份分布(Masdari and Zangakani, 2019)
2. 根据Masdari and Zangakani在2019年的研究,inter-cloud上进行scheduling的场景主要可以分为三类,即federation,multi-cloud以及hybrid cloud。本次我介绍的重点主要放在了hybrid cloud上。在先前的组会中,已经有同学在着手与隐私相结合,对hybrid cloud进行研究。我关注的领域主要是hybrid cloud中的elastic属性,例如Genez在2017年的研究,以及Yi Zhang在2018年的研究。在带有elastic属性的hybrid cloud场景中,存在一个私有云和多个公有云,当私有云的空间不足的时候,管理员可以在公共云上创建私有云的扩展。从而使用公有云的资源。
本次组会我将汇报一篇文献《Intrusion Detection for Cybersecurity of Smart Meters》,这篇文献来源于IEEE Transactions on Smart Grid。在本次组会中,我将从以下几个方面对本文献进行介绍,分别是:科研背景、科研问题、科研目的、方法、仿真结果与分析、结论、将来的工作、个人总结与思考。
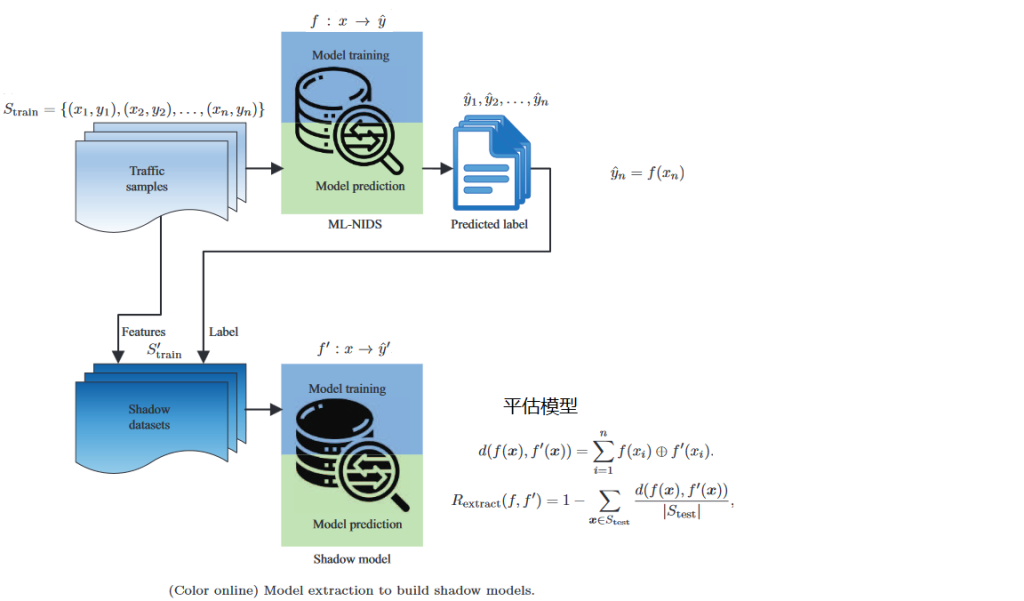
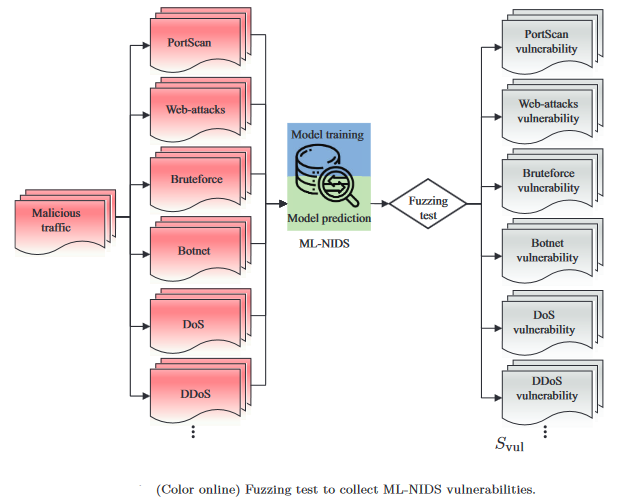
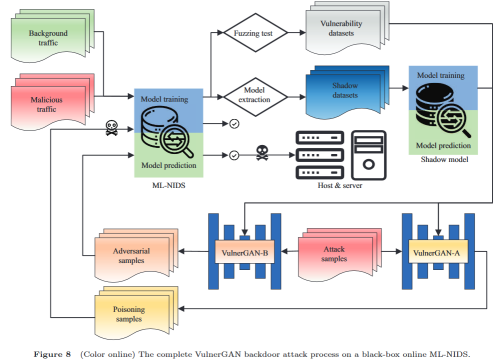
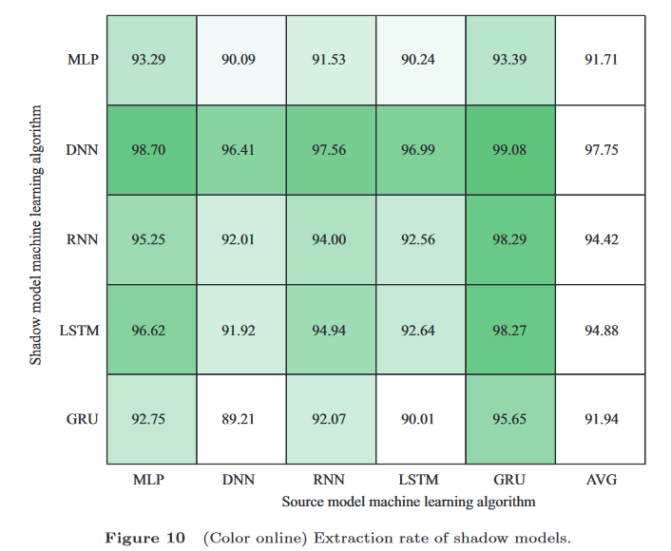
本次组会将会分享我看的一项新的研究,题目:VulnerGAN: a backdoor attack through vulnerability amplification against machine learning-based network intrusion detection systems(VulnerGAN:针对基于机器学习网络入侵检测系统的漏洞放大后门攻击)。