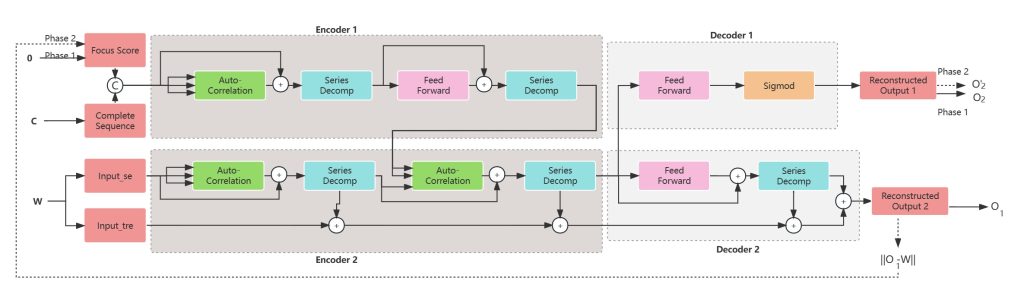
主要对“基于区块链联邦生成模型的电网用电数据合成研究”文章进行内容梳理,后期以梳理的架构完善论文内容。
科研意义
电网的数字化智能化转型,对提升电力产业核心竞争力、推动电力高质量发展具有重要意义。在这个过程中,数字技术不断发展,与电网管理的融合也逐步深入,用户用电数据的价值被深度挖掘。对用户用电数据进行分析,可以理解用户消费模式以提供更具个性化的使用服务,还可以对电力负荷进行精准预测并实时监控用电负荷行为的异常,从而提高电力系统的灵活性、可靠性和安全性。数据作为必不可少的生产要素起着关键作用。
然而,其在流通和使用中不断创造价值的同时,用户个人信息面临着严重的隐私泄露挑战。在电力能源领域,用户用电数据碎片化和孤立地存储在不同供应商中,许多供应商会因为担心数据流通的隐私泄露风险,而不愿将数据对外开放使用。另外在法律层面上,各国都在不断地推出和加强对数据安全和隐私保护相关法规的完善,因此供应商或企业外部的研究人员在访问用户用电数据时面临很多法律法规限制。这限制了用户用电数据的共享和自由流通,使得电力供应商之间形成了一个个数据孤岛,导致用电数据的训练和分析缺乏大规模的数据。
为兼顾数据隐私和机器学习模型可训练,Google 在 2016 年提出了联邦学习的概念,它是在进行分布式机器学习的过程中,各参与方可借助其他参与方数据进行联合建模和使用模型。参与各方无需传递和共享原始数据资源,仅需上传本地训练得到的模型参数,即在数据不出本地的情况下,进行数据联合训练、联合应用,建立合法合规的机器学习模型。
但联邦学习对机器学习模型训练灵活性差,每次仅能发布单一模型进行训练。训练其他模型时,即使是相同数据,也需召集所有参与方再次共同训练新模型,这极大浪费了各参与方的时间和计算资源。联邦学习依赖于单一的中心服务器,容易受到中央服务器故障或攻击的影响。一旦中心服务器被攻击者瘫痪,则整个数据共享过程便会中断,还可能造成严重的隐私泄露。开放网络中用户互相之间缺乏信任,很难建立数据共享的基础。
科研目的
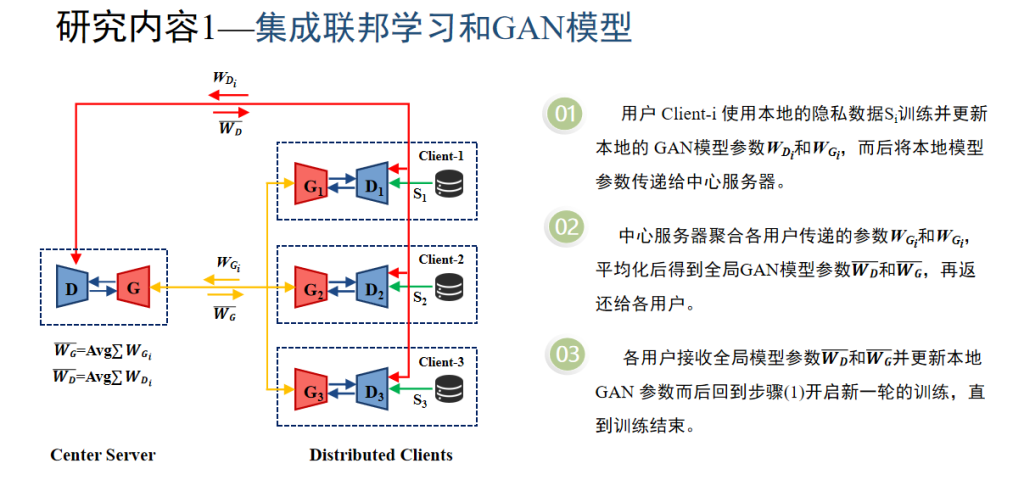
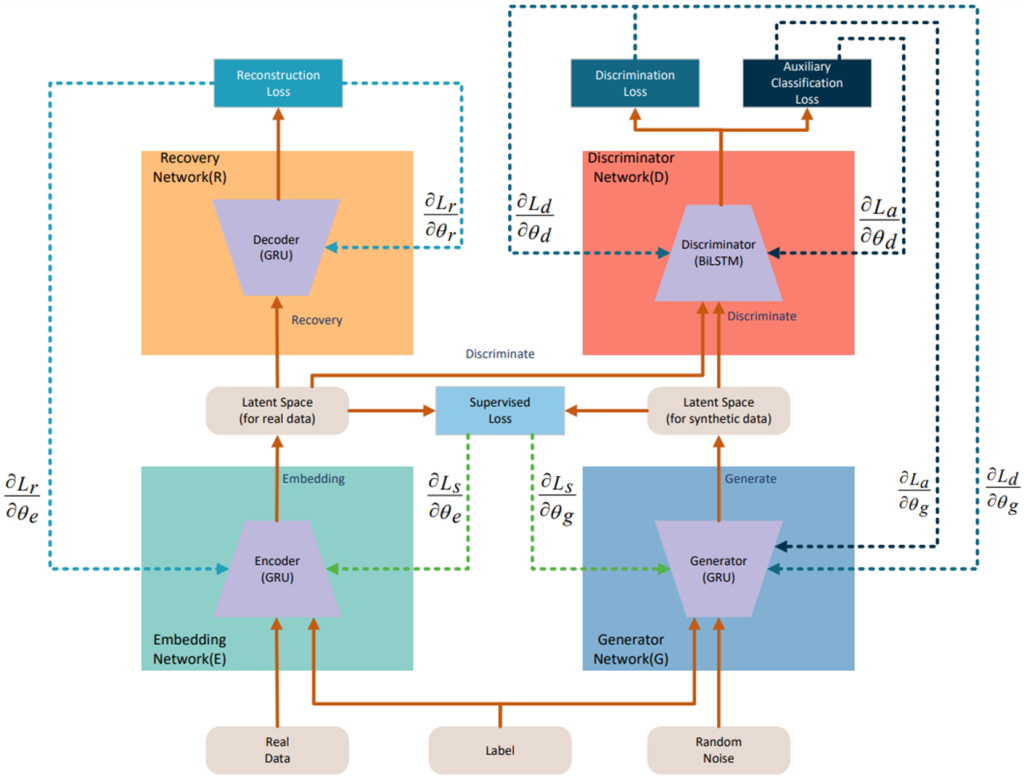
01 将联邦学习和GAN模型进行集成,以联邦学习的方式使用多方数据训练生成模型GAN,所生成的合成数据可灵活地进行多种机器学习任务,以提供更加智能化的服务。
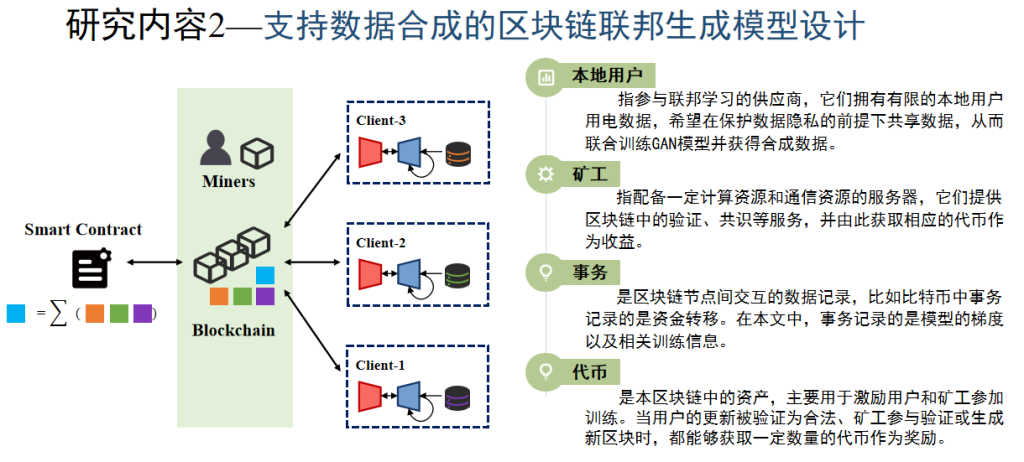
02 提出一种支持数据合成的区块链联邦生成模型,由区块链为联邦GAN模型训练提供一个信任交互的平台,对参与者训练参数的接收和下发进行统一调度,并进行参数聚合。提高了用户间的信任度和整个训练网络的健壮性。
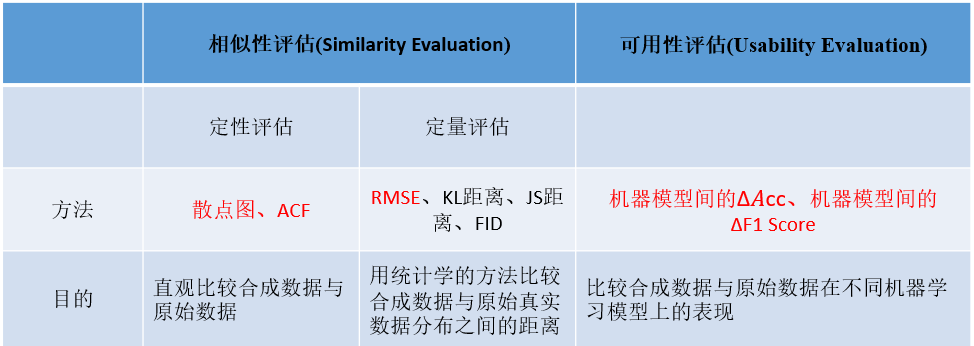
03 展开了预测用户负荷和分析用户行为的机器学习任务,利用爱尔兰CER的真实数据对支持数据合成的区块链联邦生成模型进行了综合评估,并验证了模型的有效性。
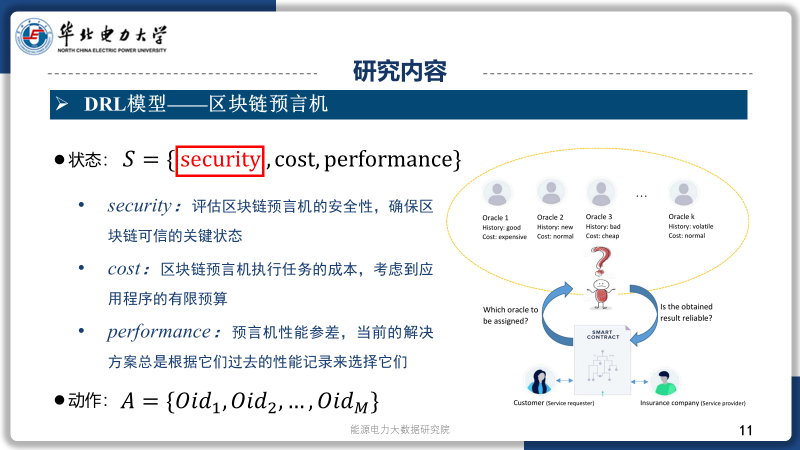
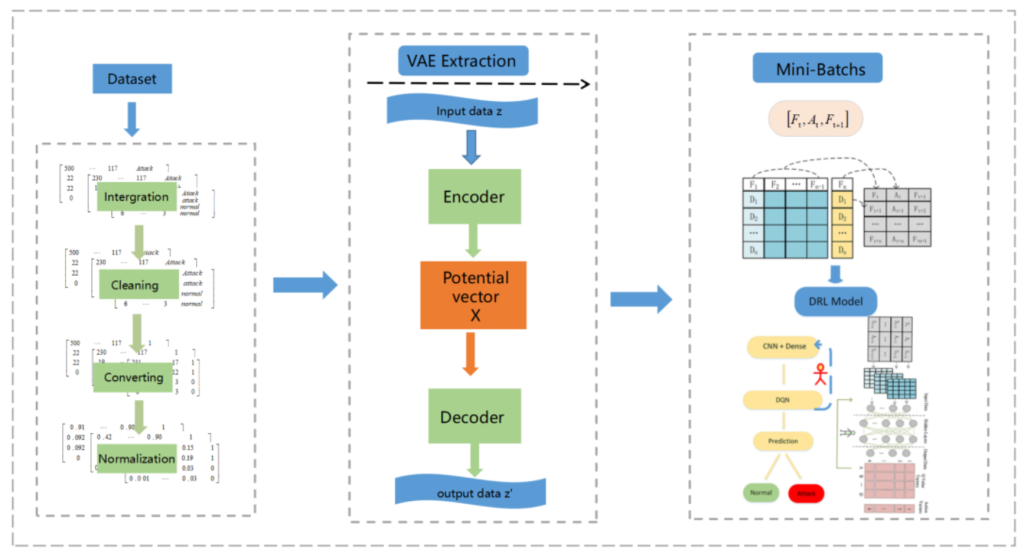
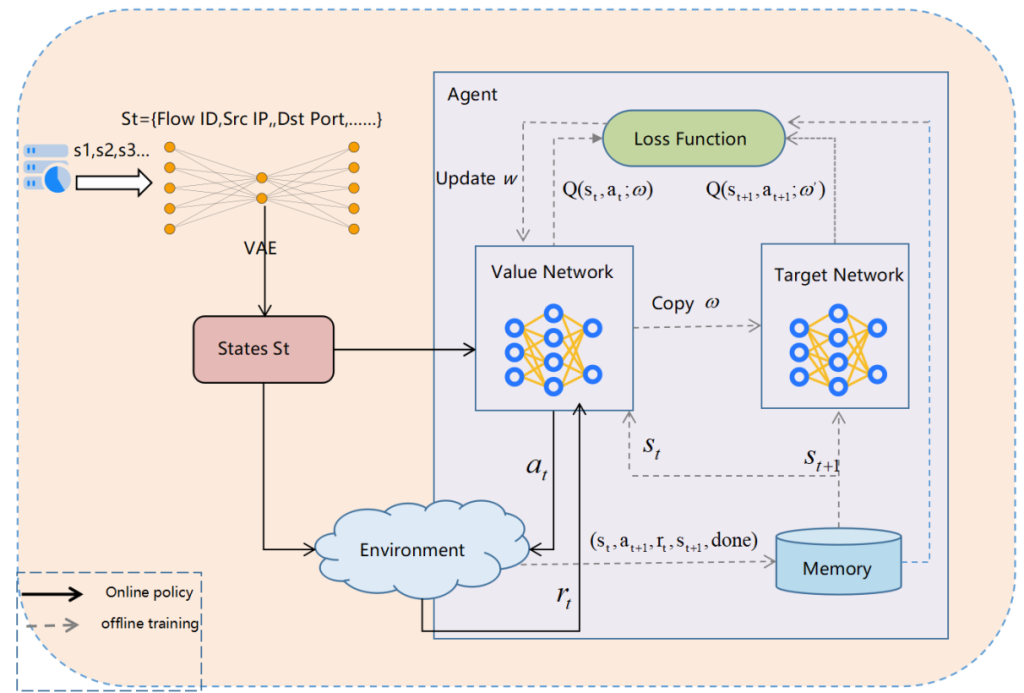
研究内容