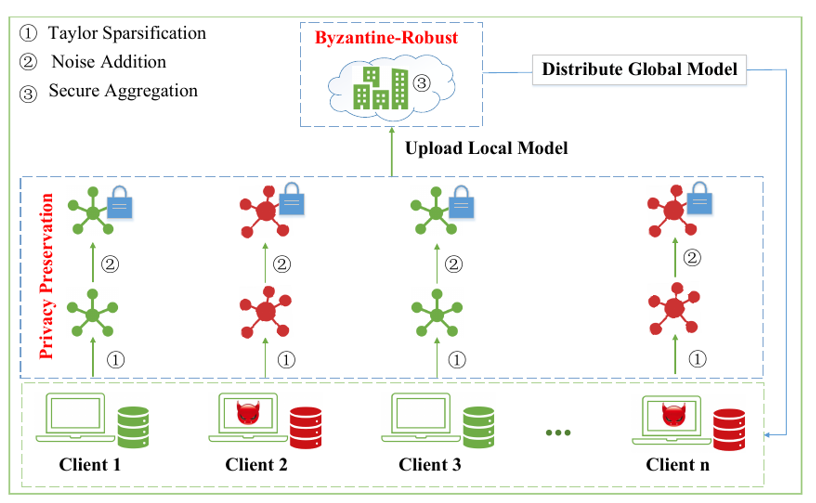
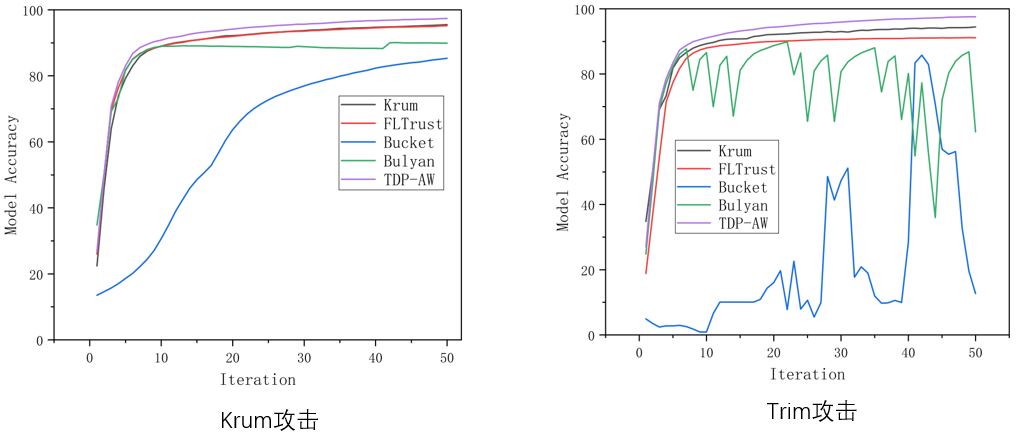
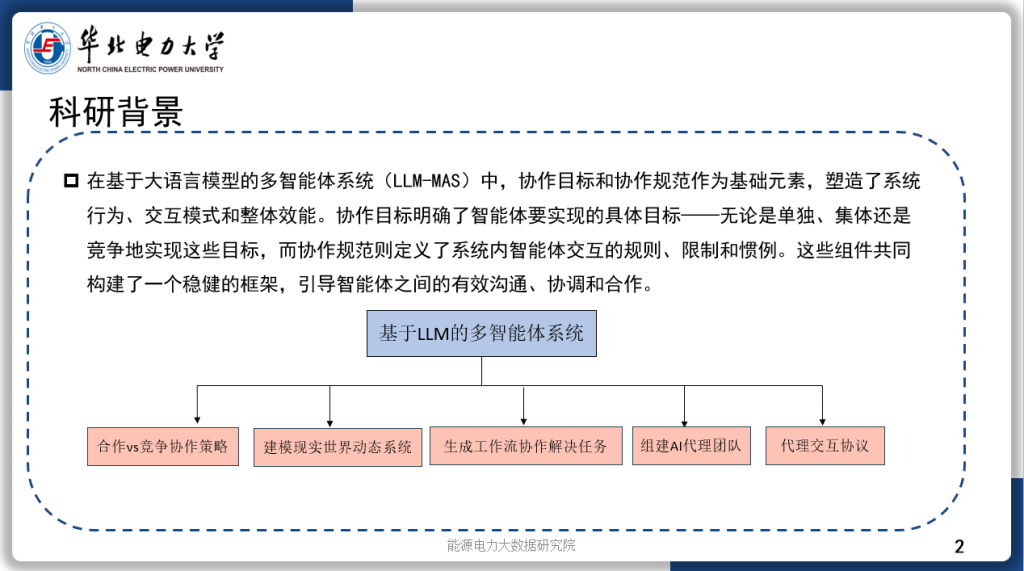
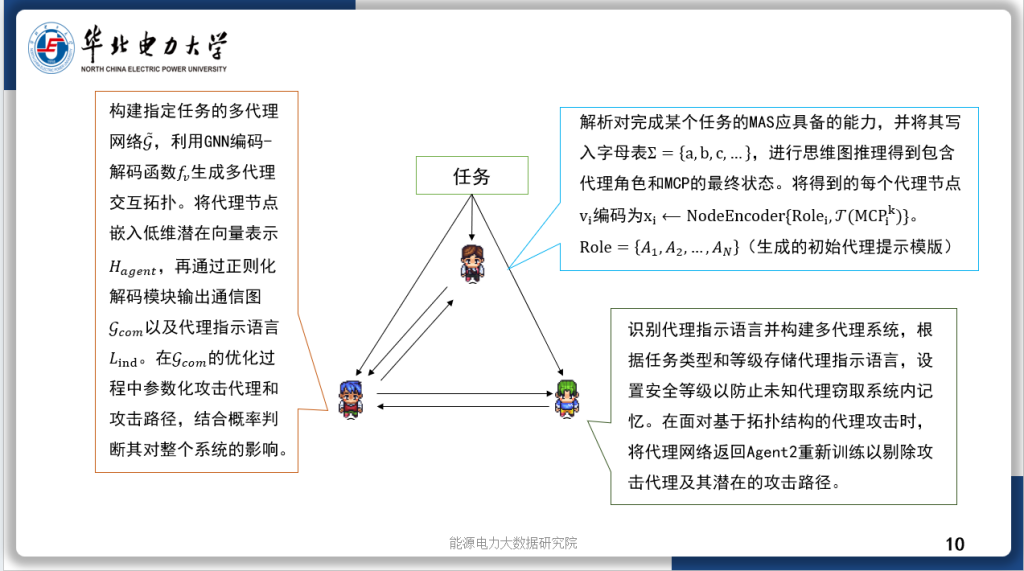
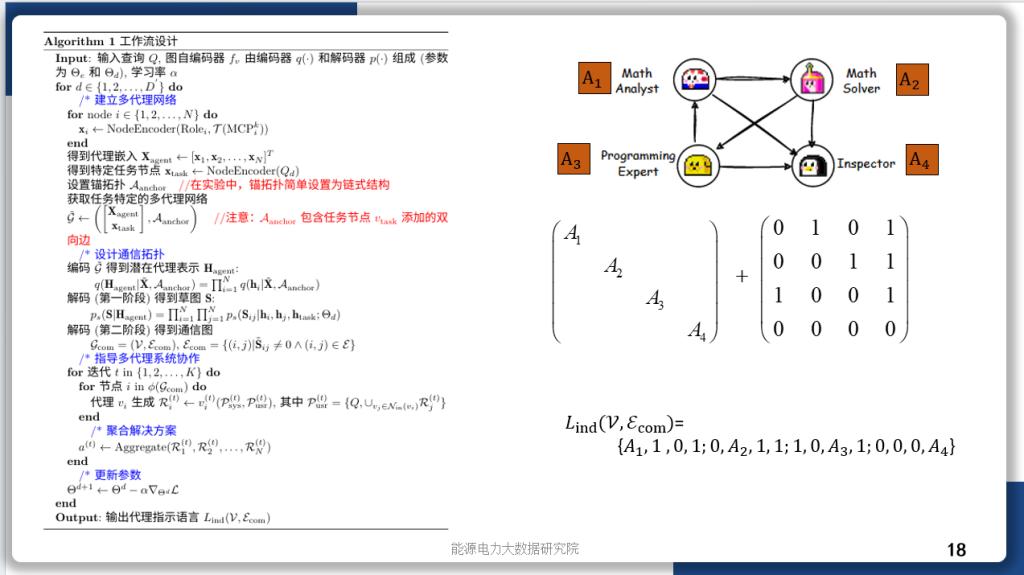
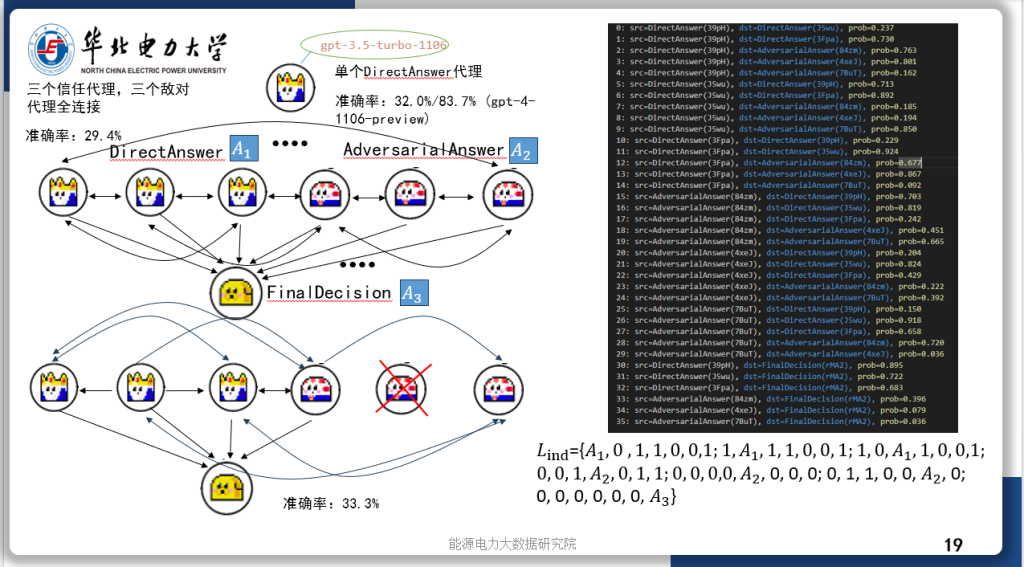
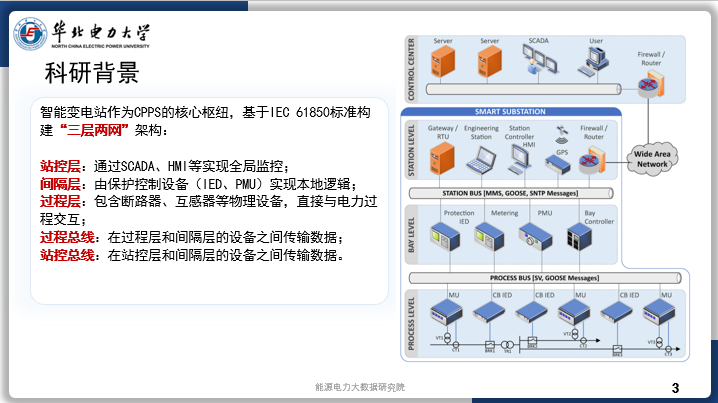
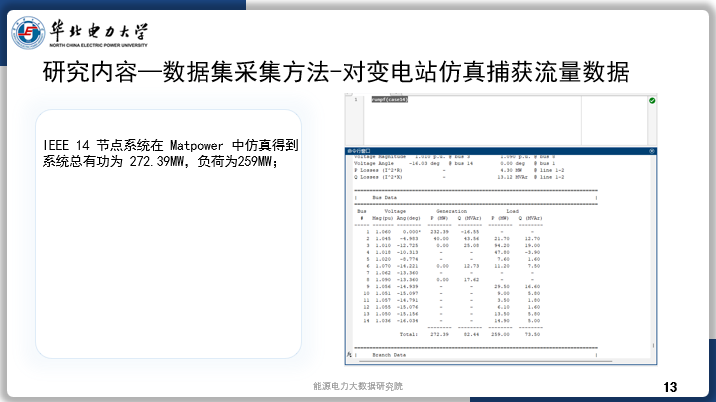
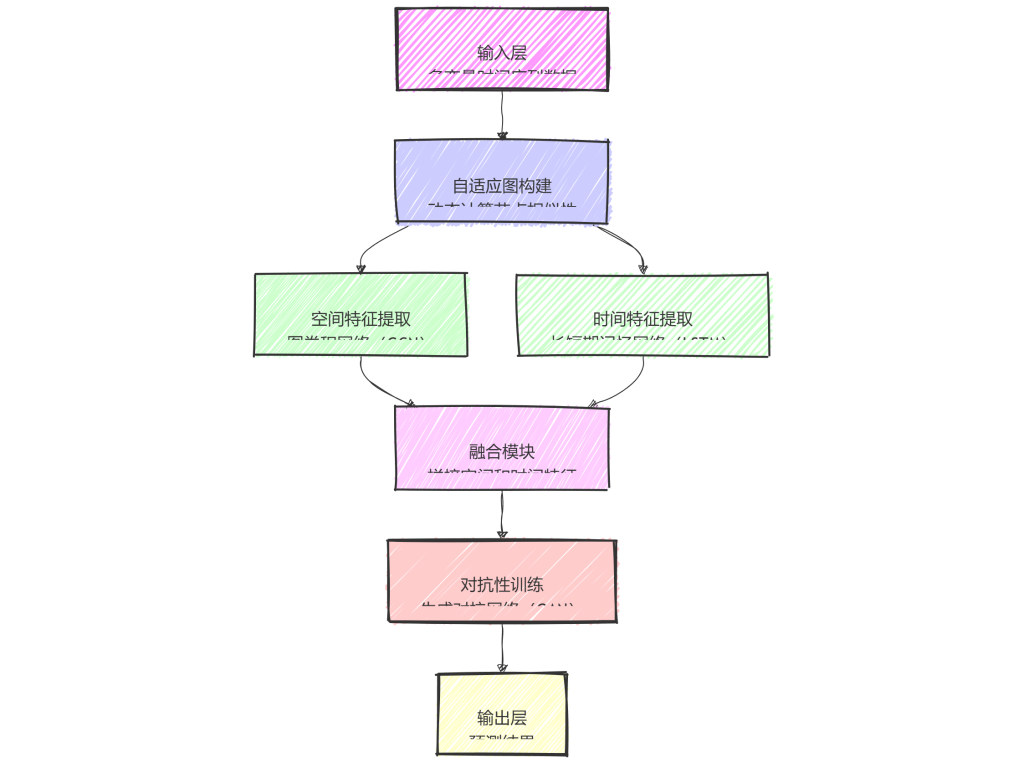
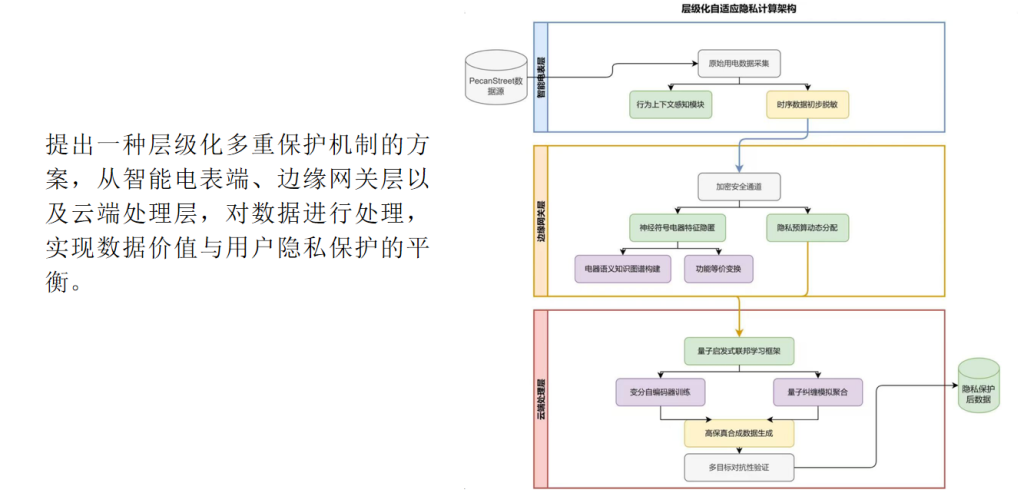
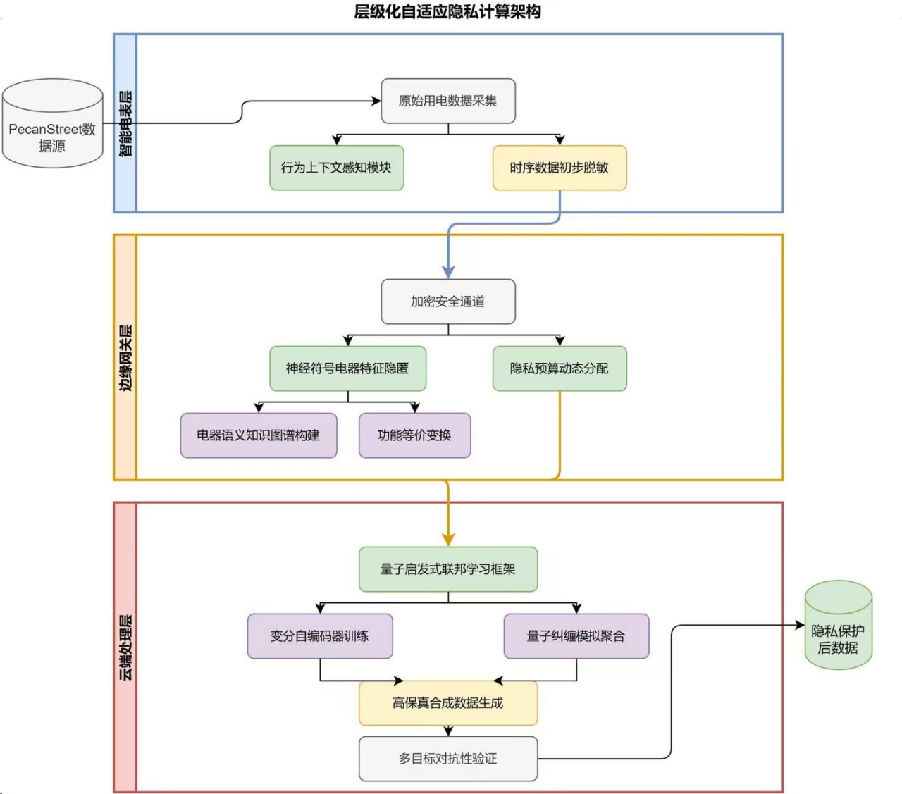
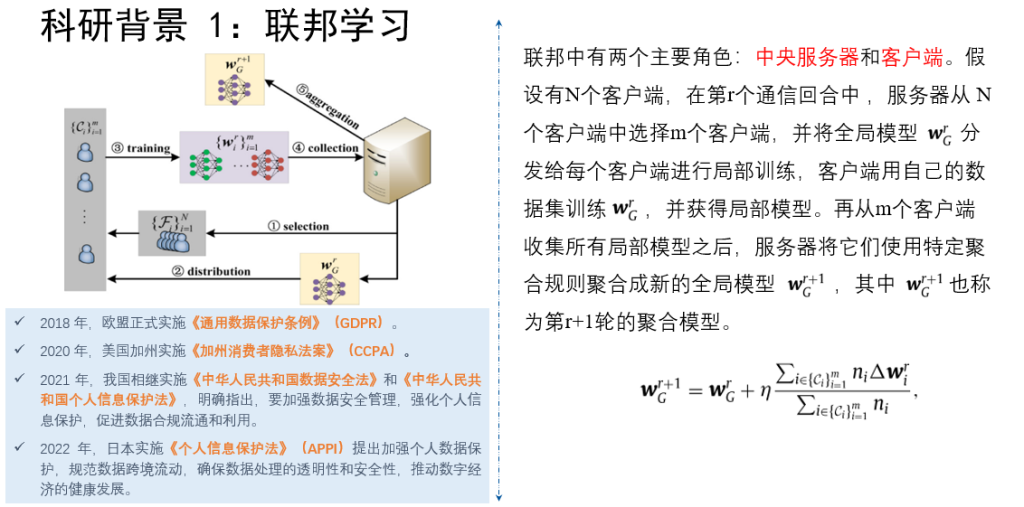
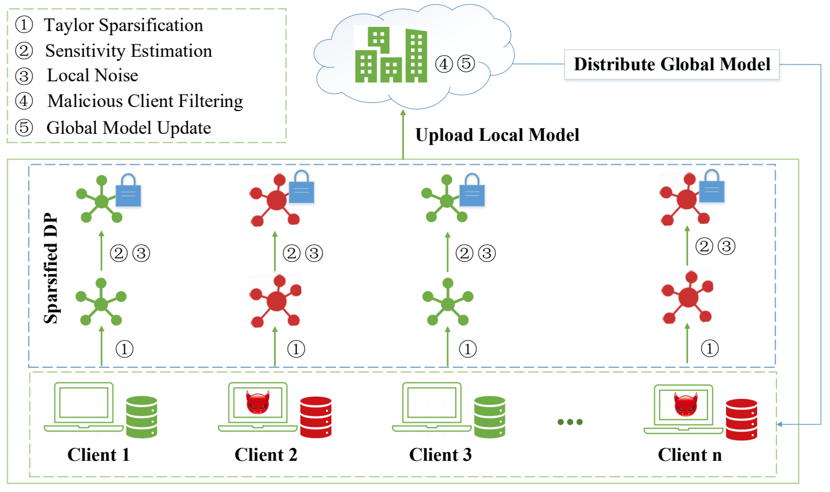
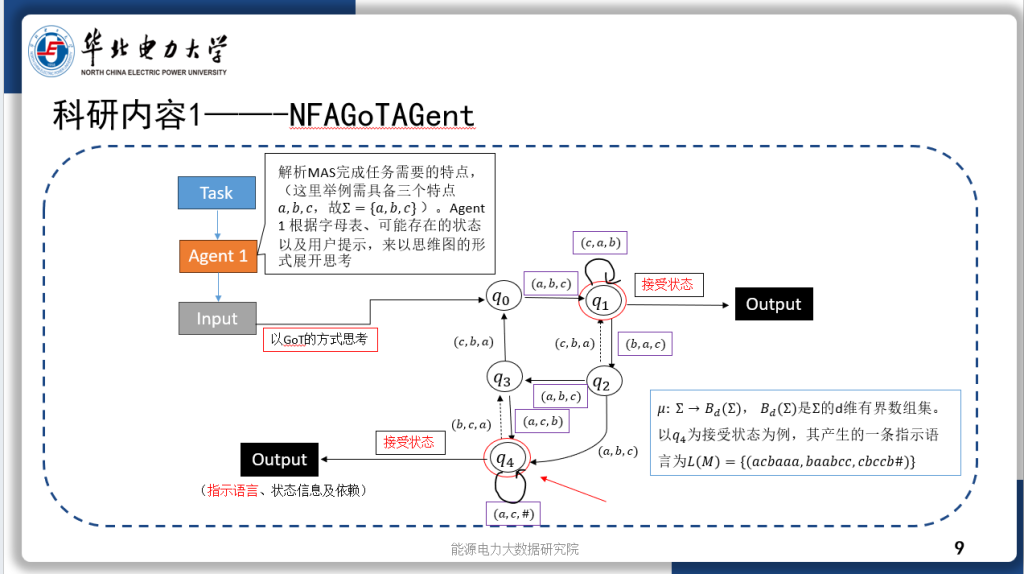
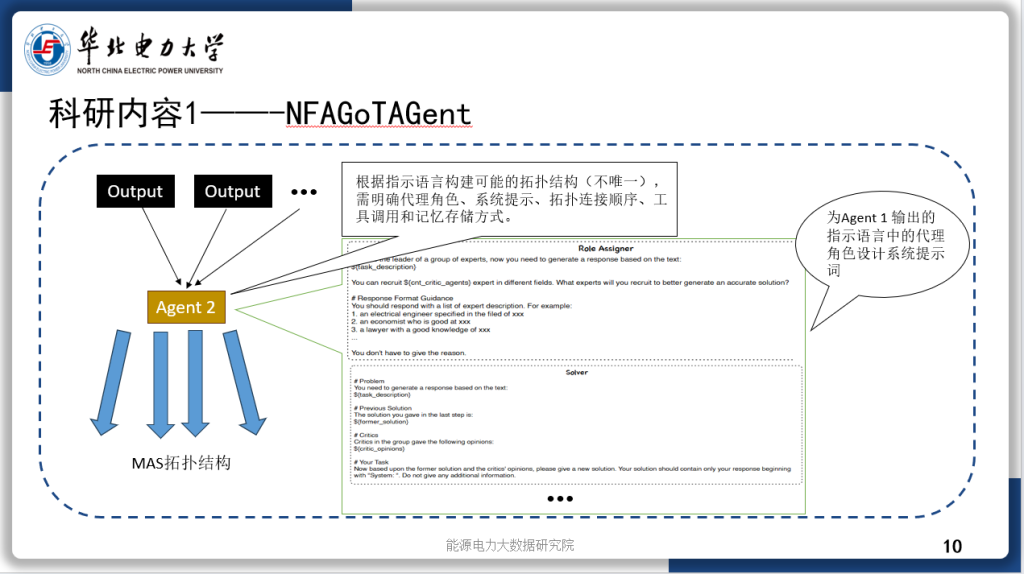
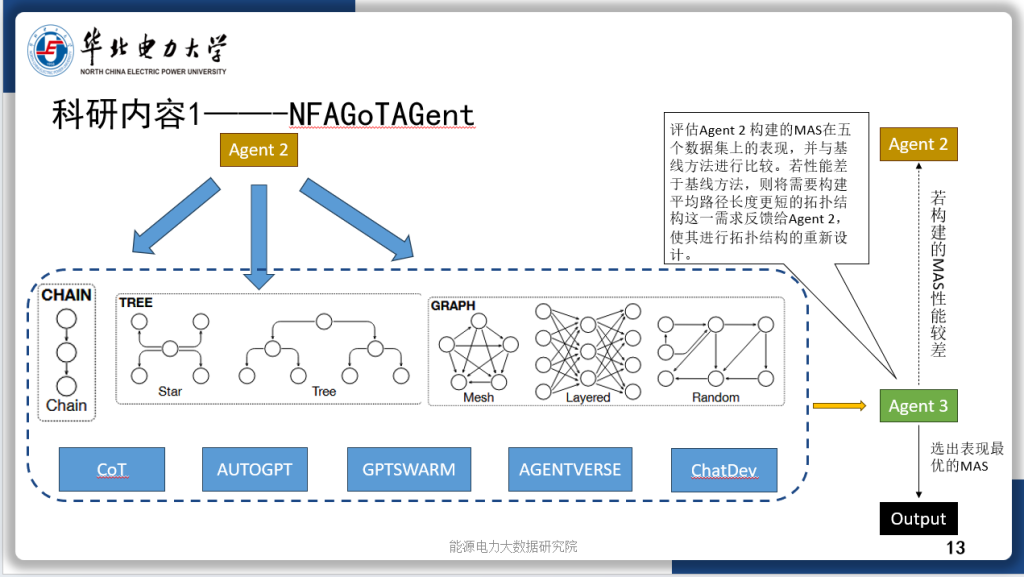
今天汇报的是我的研究《基于强化学习自适应采样的扩散模型居民负荷生成加速方法》。
科研背景
为了实现碳中和和可持续发展,电网正在经历大规模的绿色转型:随着风电、光伏等可再生能源比例快速上升(2023 年我国可再生能源装机超过 50%),系统调度面临更强的不确定性与波动性。无论是实时负荷预测、需求响应,还是微电网/虚拟电厂的协调优化,都离不开大量高精度的时序负荷数据——不仅要覆盖峰谷差异,还要反映居民、商企、工业等不同用电侧在分钟级甚至秒级尺度的动态变化。与此同时,为了构建电网数字孪生、开展大规模仿真和场景测试,也需丰富多样的负荷曲线,以支撑算法训练和风险评估。
智能电表可实现分钟甚至秒级的采样,精准记录电流、电压、功率因数及时戳等细粒度负荷特征;这些数据不仅有助于负荷特性分析、错峰填谷,还可与气象、用户侧可控负荷、储能数据融合,提升预测与调度精度。
然而,在GDPR、数据安全法等法规约束下,以及考虑到用户隐私和数据安全,电力公司往往无法开放全量历史数据;再加上采集维护成本高、归档标准不统一、不同区域间数据分散存储等问题,导致难以获得规模化、长时序的“真实”负荷数据供模型训练和仿真使用。
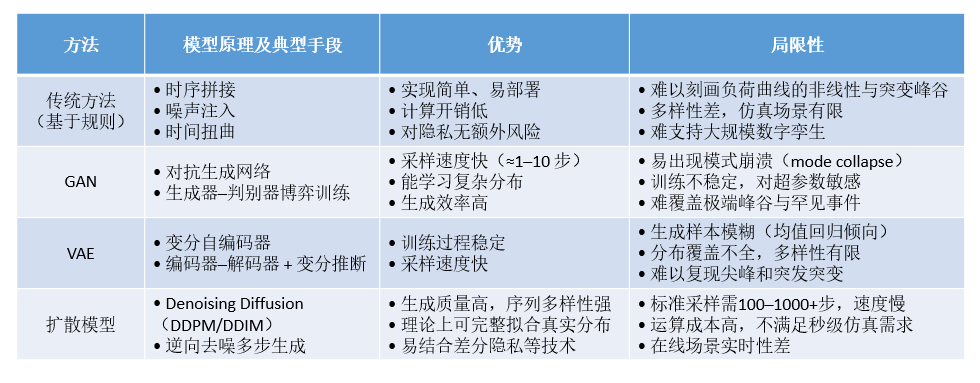
合成数据(synthetic data)技术可在隐私保护前提下,生成与真实负荷统计分布高度一致的时序序列,已成为智能电网数字孪生、算法测试和在线决策的关键支撑。
科研问题
•时序特征保持:需要设计一种数据合成方法在合成负荷数据中准确再现峰谷、周期性和突变等关键时序特征,以满足在线调度和需求响应对数据时效性与精度的要求
•采样效率提升:扩散模型虽能生成高质量序列,但需上百乃至千步采样,速度无法满足实时仿真场景,因此需要设计一种自适应采样策略来大幅缩短生成延迟
科研目的
1.针对电力系统时序负荷生成需求,提出一种基于强化学习的扩散模型自适应采样方法,实现对电力负荷序列的快速、精准合成。
2.在确保合成数据质量、时序稳定性和多样性的前提下,将采样步数控制在 50 步以内,使生成延迟满足在线调度和大规模仿真的实时性约束。