本次组会对近期的研究工作《面向分布式电网异常检测模型的隐私保护》进行汇报,主要从科研背景、科研问题、科研目的以及研究进展这几方面来阐述。
科研背景
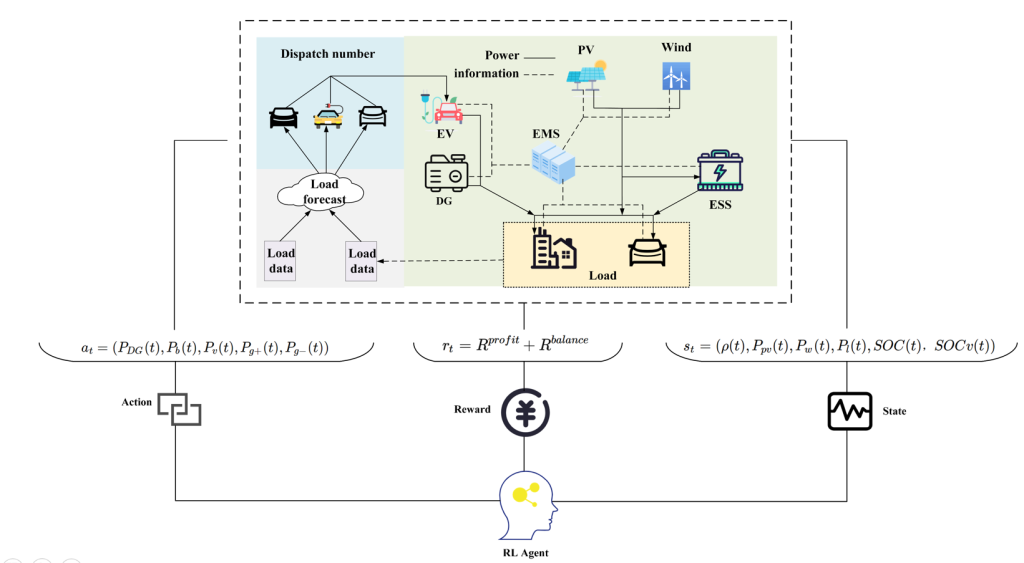
- 智能电网:智能电网将信息和通信技术集成到传统电网中,以管理电能的产生、分配和消耗。尽管它有许多优点,但它面临着重大挑战,例如检测网格中的异常行为。识别异常行为有助于发现不寻常的用户功耗、基础设施故障、停电、设备故障、能源盗窃或网络攻击。
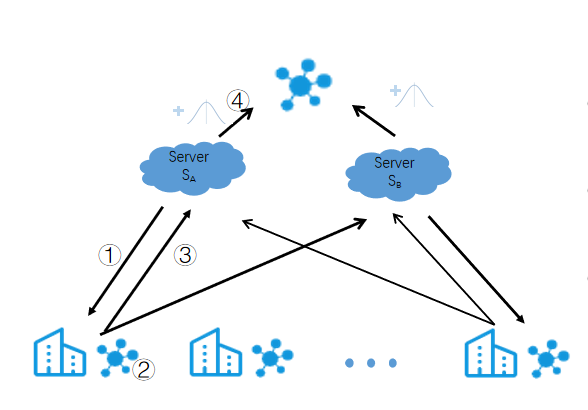
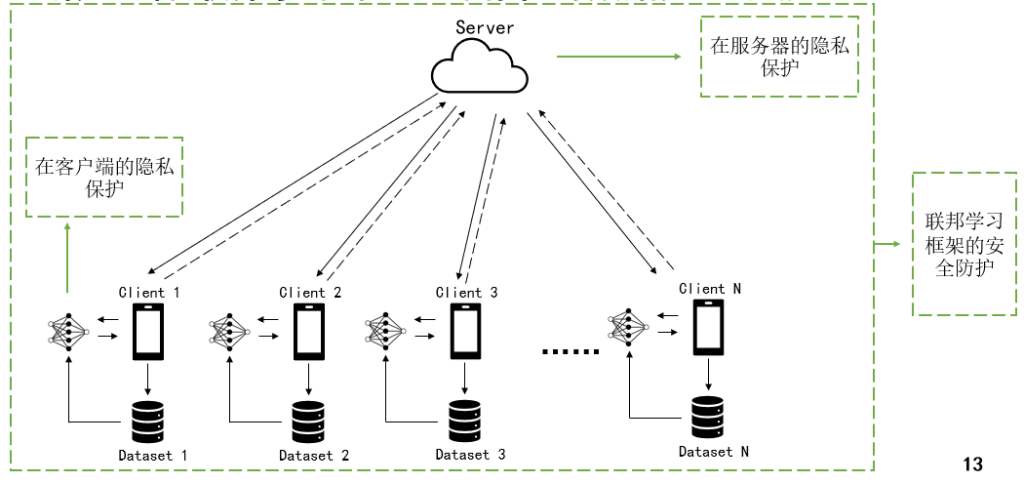
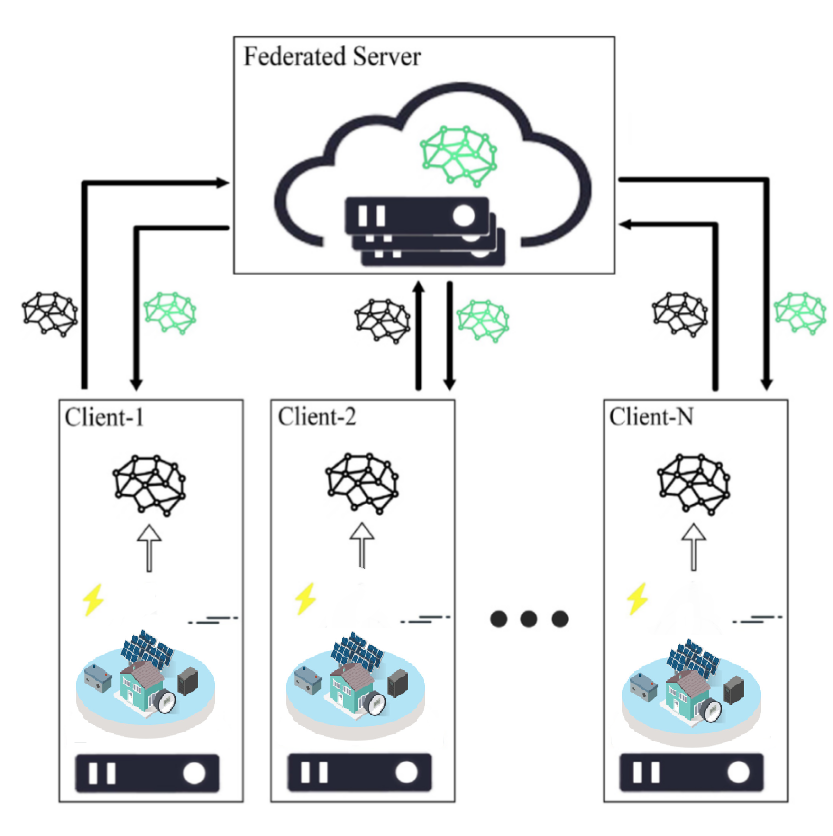
- 异常检测:基于机器学习的智能电表数据技术在异常检测中显示出显著的效果。然而,传统的基于机器学习的异常检测需要智能电表与中央服务器共享本地数据,这引起了对数据安全和用户隐私的担忧。在分布式电网的场景下,我们想要尽可能地保证用户的隐私,基于联邦学习(FL)的智能电网异常检测受到越来越多的关注。
科研问题
随着联邦学习在各种分布式场景下的应用,联邦学习在异常检测方面存在以下挑战:
1. 对于联邦学习来说,它的通信代价远大于计算的代价,边缘设备和服务器之间通常是远程连接,带宽很低网络延迟很高,对它的实时性有着很大影响,所以我们要提升联邦学习的通信效率。
2. 由于联邦学习是整合所有数据孤岛中的数据对其进行分析挖掘,这就要求我们所有的参与节点都是可信的,在传统联邦学习中结点的可信程度决定着联邦学习的鲁棒性,这样就需要对联邦学习的聚合算法进行调整,让它可以抵御恶意节点的攻击。
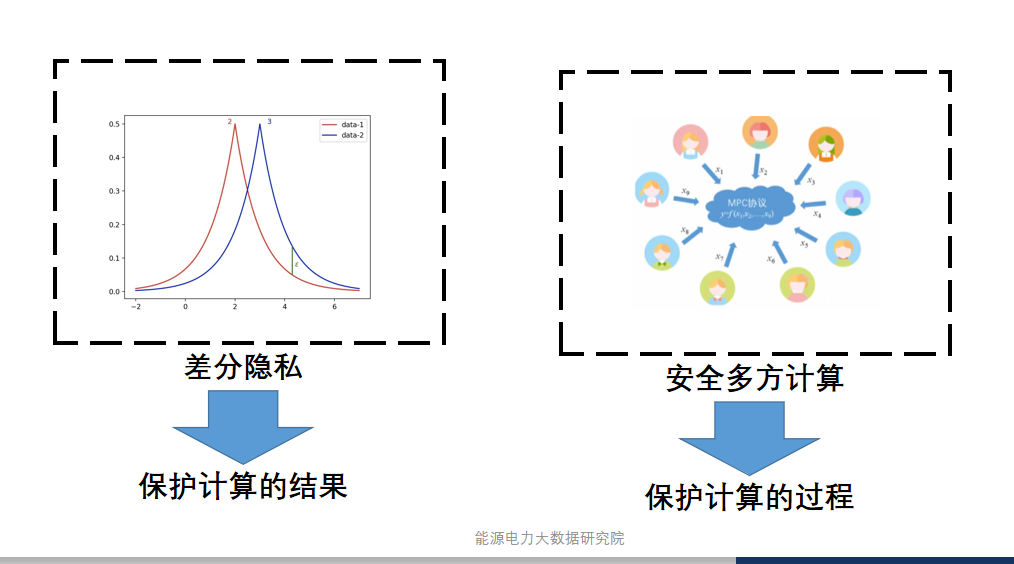
3。相关文献证明了如果我们需要训练一个有效的模型,那在训练的过程中我们所使用的梯度是和原来的数据密切相关的,也就是我们在使用联邦学习时,虽没有泄露原始的数据,但仍传递了原始数据的相关信息,对其进行隐私保护是有着很重要意义的,这也是我们所研究的问题。
科研目的
本次研究旨在提出一种面向分布式电网异常检测模型的隐私保护方法,使用同态加密方法,通过对梯度进行加密来保护隐私,也不影响联邦学习的效果。具体来说,就是接将原文加密,然后联邦学习的中央服务器能够在密文上进行各种运算,最终得到结果的密文也就是我们聚合之后的梯度的加密密文。同态加密能够在不影响训练效果的情况下保护隐私,但是我们的加密的过程大大增加了我们所需要传输的数据量,因此还需要对中间传输的数据进行压缩,从而实现通信成本和隐私保护均衡的分布式异常检测模型。
研究内容
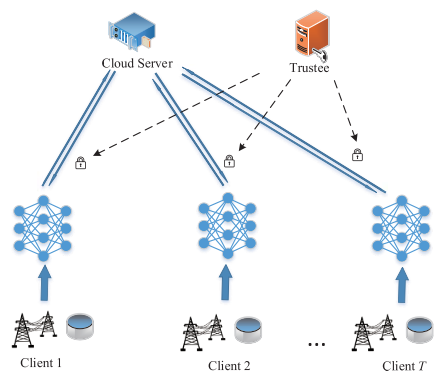
具体研究内容将在组会中讲述
研究计划
- 设计实验实现对联邦Transformer中间参数进行压缩,取得初步实验结果。
- 对原模型和压缩后的模型的中间参数进行同态加密,比较通信成本。