今天我将继续就《基于扩散模型的合成数据研究》进行介绍
科研背景
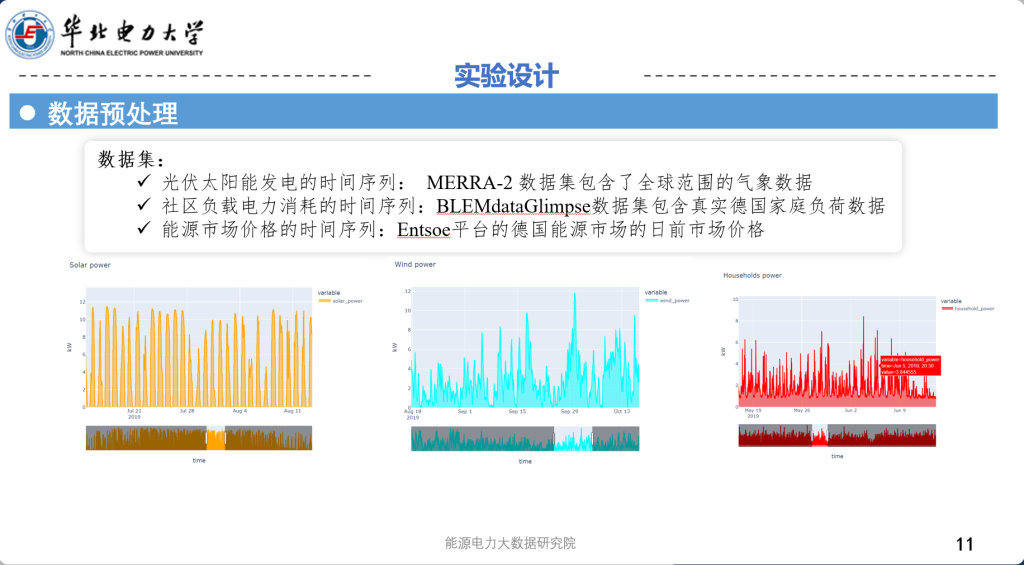
•为了构建新一代电力系统以实现碳中和目标,有必要全面提升电网的数字化和智能化水平。这不仅是应对全球气候变化的重要举措,也是满足未来能源需求、推动经济和社会可持续发展的关键途径。在此背景下,智能电表作为一种先进的计量基础设施,得到了广泛部署。智能电表通过实时监测和采集用电数据,不仅能够促进能源流与信息流的深度融合,还能为电力系统提供更加高效和可靠的支持。尤其在住宅用电负荷特征(residential load profile)方面,智能电表的应用为电网的调度和管理带来了显著的改进。
•
•智能电表能够精确记录每个家庭的用电情况,包括负荷波动、用电时间段等数据。这些数据帮助电力公司更准确地了解各类家庭的用电模式,从而为电网的负荷预测和优化调度提供依据。通过分析住宅负荷曲线,电力公司能够更好地识别电力需求的高峰和低谷,优化电力供应,减少能源浪费。此外,智能电表还为用户提供了详细的用电数据,帮助他们更好地管理家庭能源消费,推动节能减排。通过结合智能电表与先进的数据分析技术,电力系统可以实现更精确的负荷预测和实时的负荷调度,从而提高电网的效率和可靠性,支持可再生能源的集成,最终推动能源的绿色转型和碳中和目标的实现。
科研问题
1.提出了一种基于条件扩散模型(conditional diffusion models)的负载曲线合成方法。该方法能够根据用户的条件信息,实现高质量的负载曲线合成。
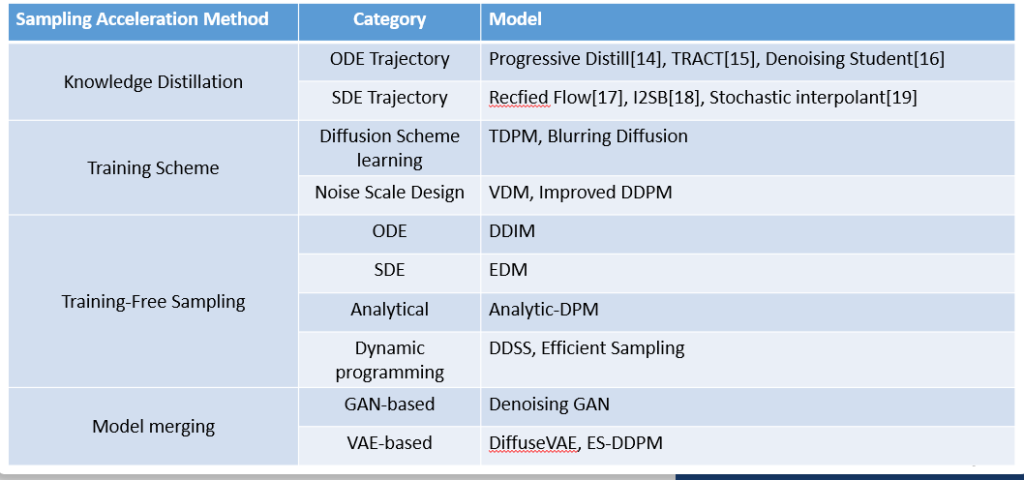
2.同时,我们设计了一种新的网络结构使sampling的过程更加高效(fast sampling)。