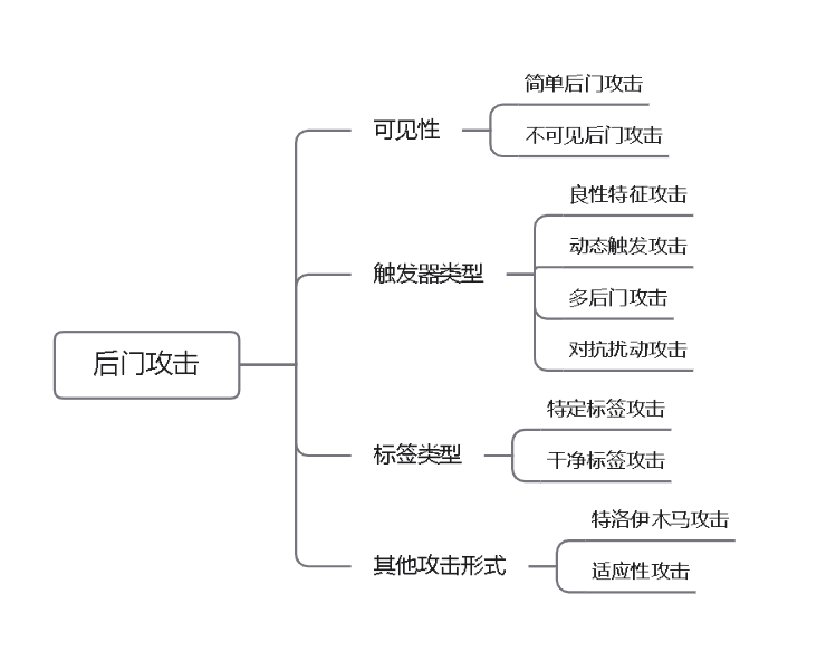
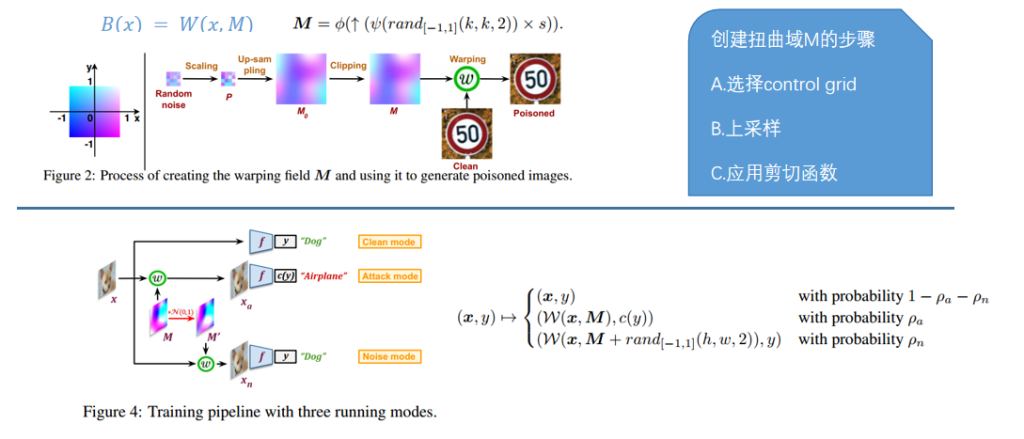
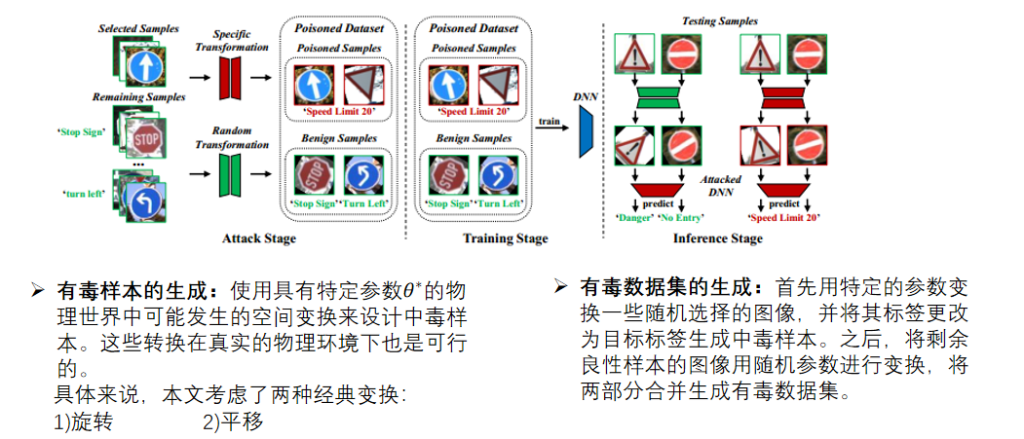
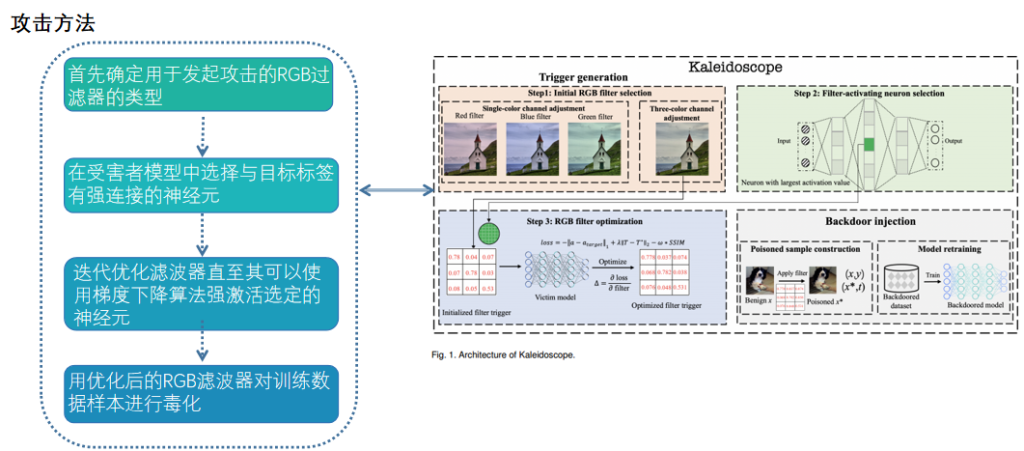
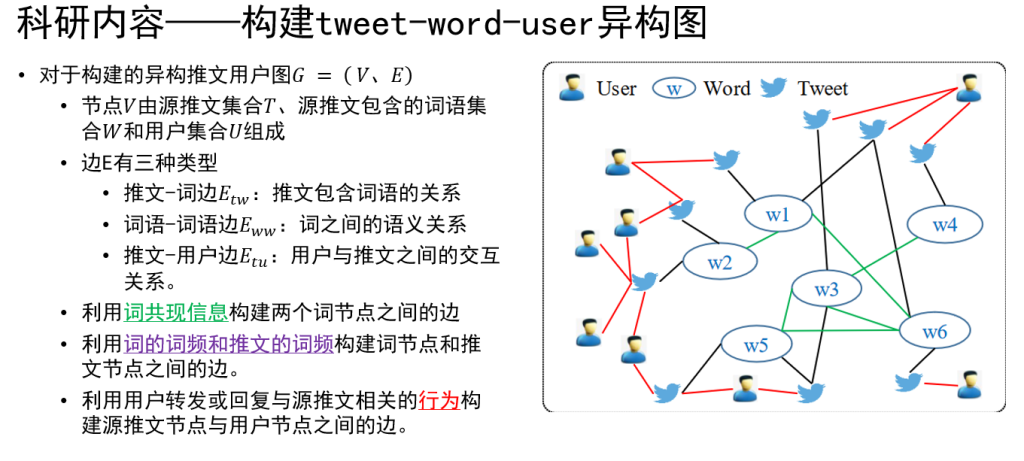
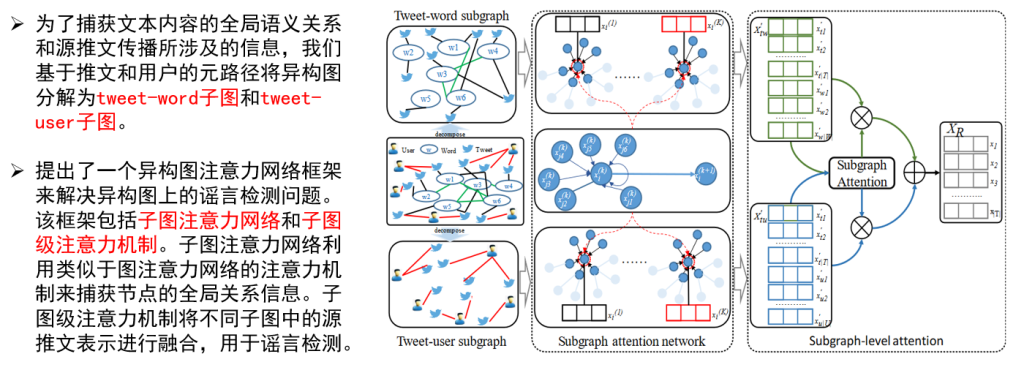
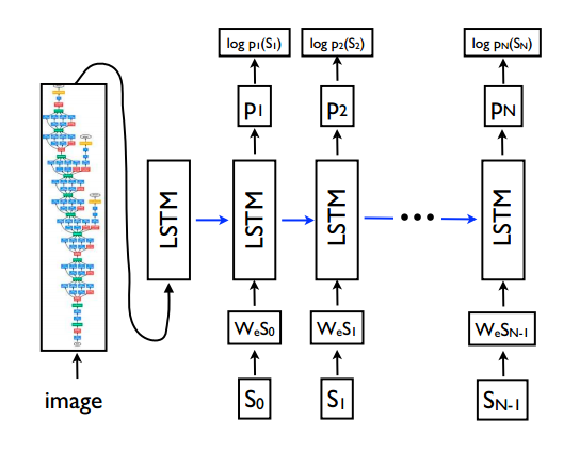
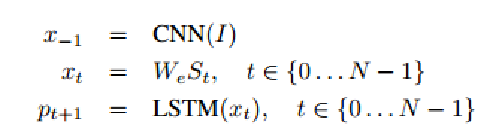电池储能系统(Battery Energy Storage System,简称BESS)是一个利用采锂电池/铅电池作为能量储存载体,一定时间内存储电能和一定时间内供应电能的系统,而且提供的电能具有平滑过渡、削峰填谷、调频调压等功能。受滥用、外部环境和操作条件的耐受性差的影响,电池系统可能会发生各种故障,导致电池加速退化,甚至发生安全事故,如热失控(TR)、火灾和爆炸。
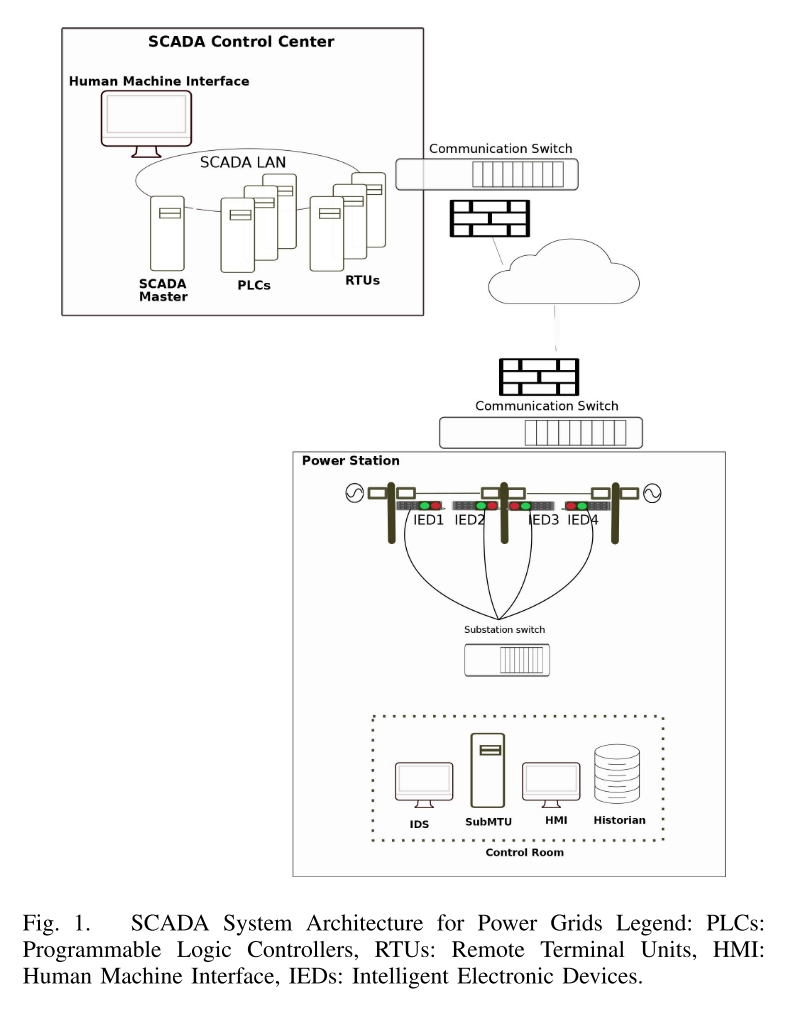
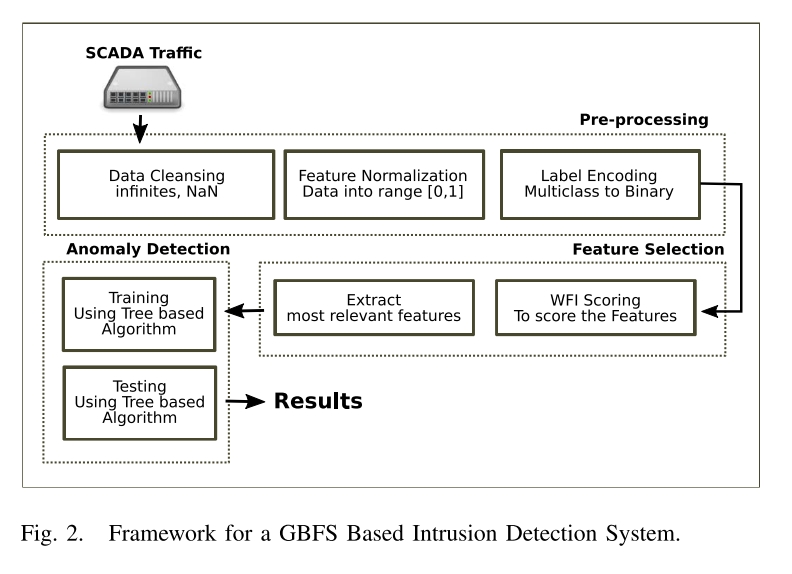
电网的设计目的是以高效和及时的方式发电和配电,而不是关注系统关键基础设施的安全方面。然而,互联和远程访问的增加使电网面临内部和外部攻击的风险。实时网络攻击可以破坏整个电网。SCADA(Supervisory Control And Data Acquisition)系统,即数据采集与监视控制系统,容易受到网络攻击威胁。