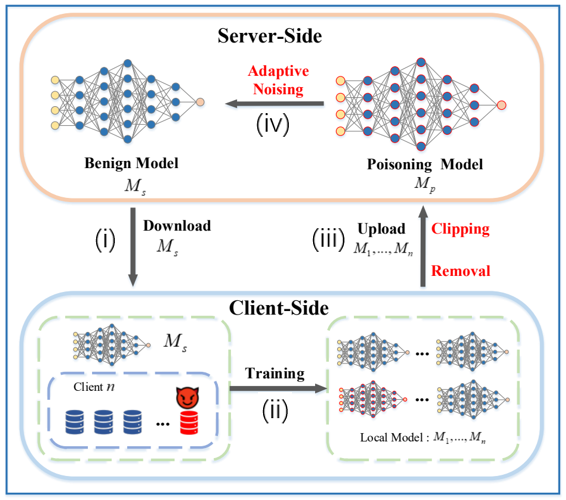
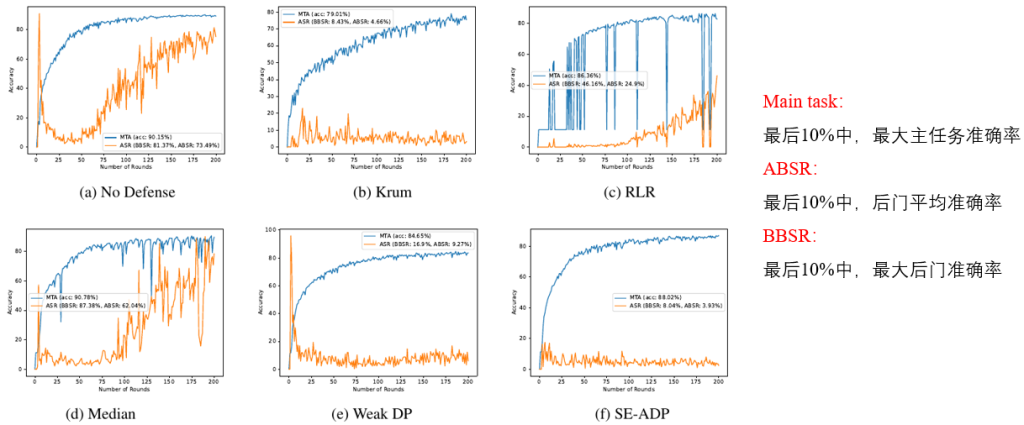
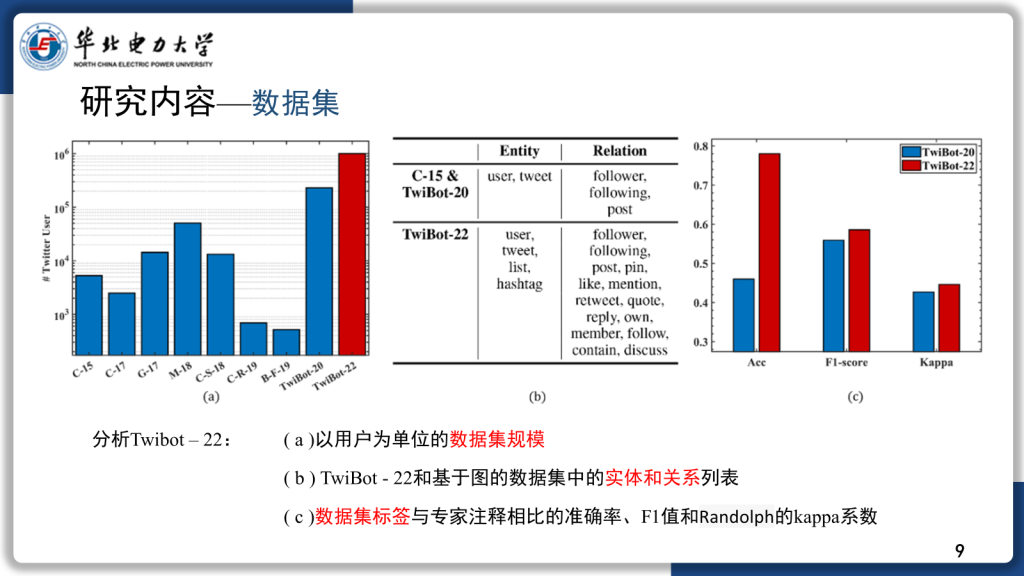
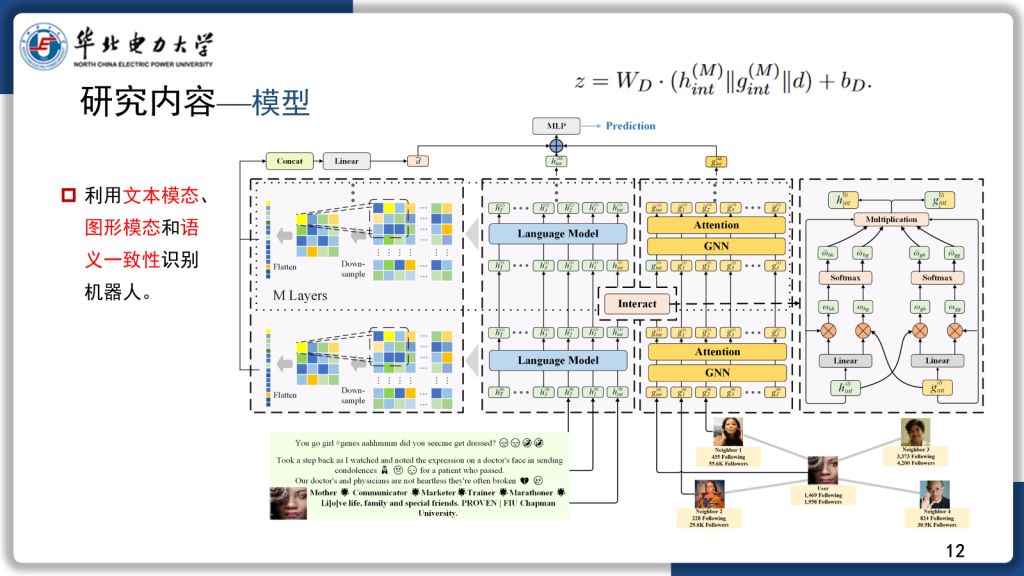
科研背景
随着分布式能源 (Distributed Energy Resource,DER) 单元的不断接入,传统配电网的单向电力传输方式正逐渐向主动配电网的双向电力传输方式转变,这种转变对配电网的感知、控制和协调能力提出了更高的要求。单个DER额定容量很少,但是其渗透性在不断提高。为减小风电和太阳能光伏等DER单元间隙性发电对用户侧电能质量的影响,配电网给众多馈线支路安装大量的智能电子设备 (IED)和远程终端单元(RTU) 对DER运行状况进行实时监测感知。一旦攻击者入侵至配电网通信网络,并利用恶意漏洞控制DER 单元,可能造成发电节点失效和大规模停电事件,产生不可估量的经济损失,甚至对人员造成伤亡.
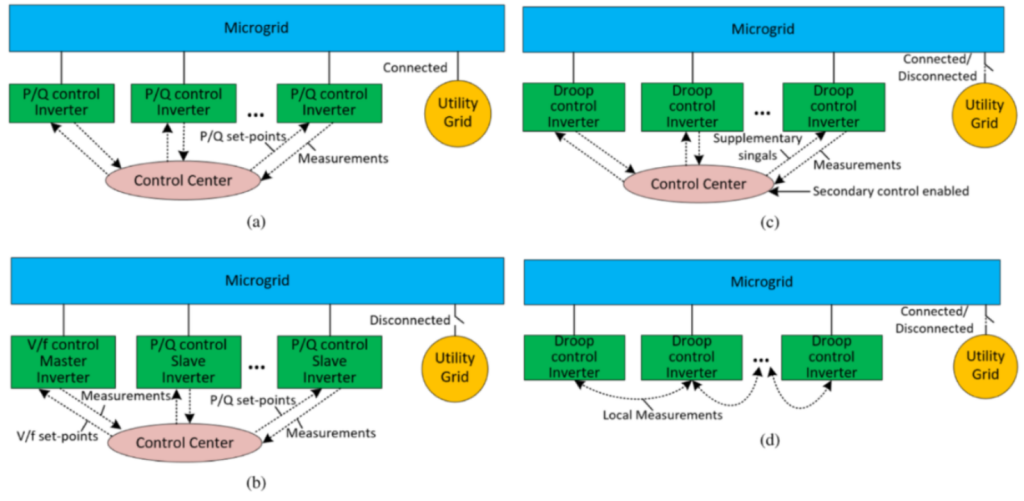
基于DER智能逆变器的电网级架构
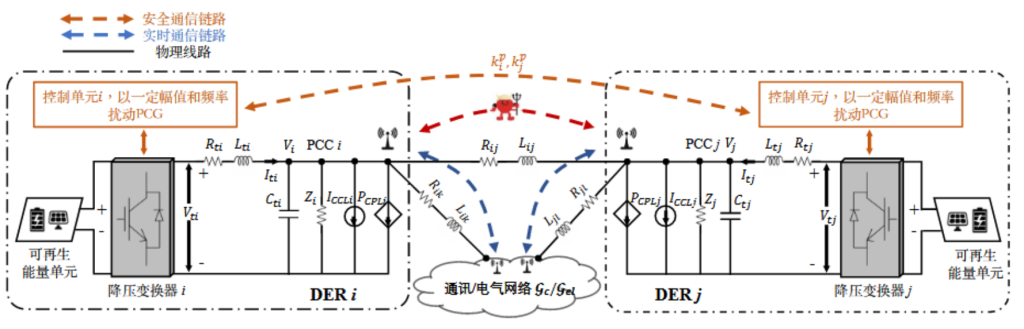
攻击模型
科研问题
1.基于模型的检测方法,易被攻击者识破:基于模型的被动式方法十分依赖于准确的模型知识如配电网网络拓扑和线路参数等。这些模型知识在配电网运行时变化很小, 因此可被当作静态信息。但是,一旦攻击者了解了防护方法的工作原理,且得到了这些静态信息,将极有可能使得基于模型的被动式方法失效
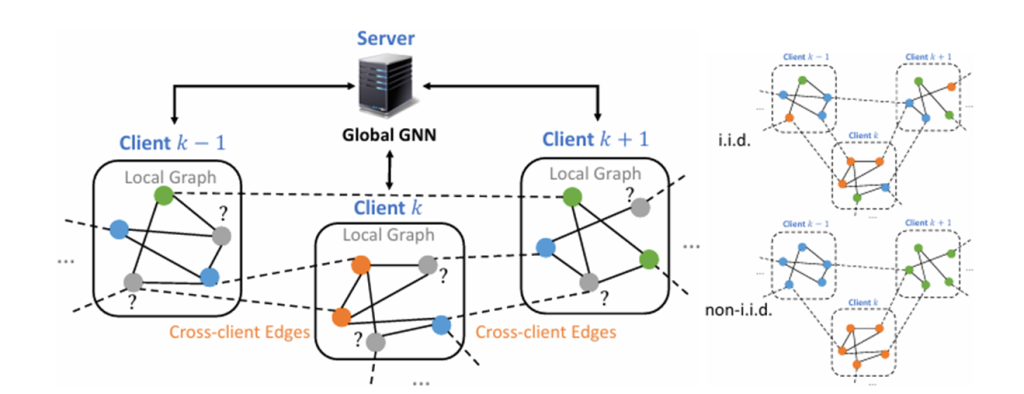
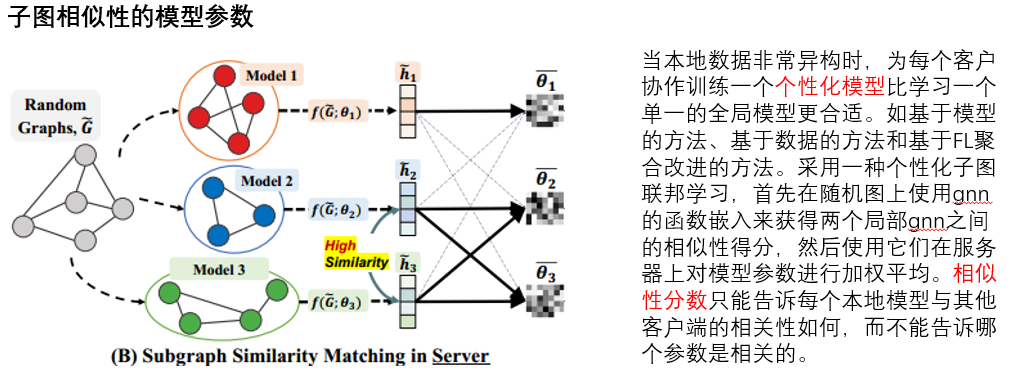
2.基于数据的检测方法,忽略了电气系统的物理拓扑结构。电力系统的不规则拓扑结构已被建模为图形,每个网格总线和分支分别直观地抽象为顶点(节点)和边。每个节点的邻域是相邻节点的集合,其中包括节点本身和通过边连接到它的节点。而在数据驱动的检测方法中,往往忽略这种拓扑结构,利用这种利用电网的底层图结构来提高检测性能是可行的。
研究目的
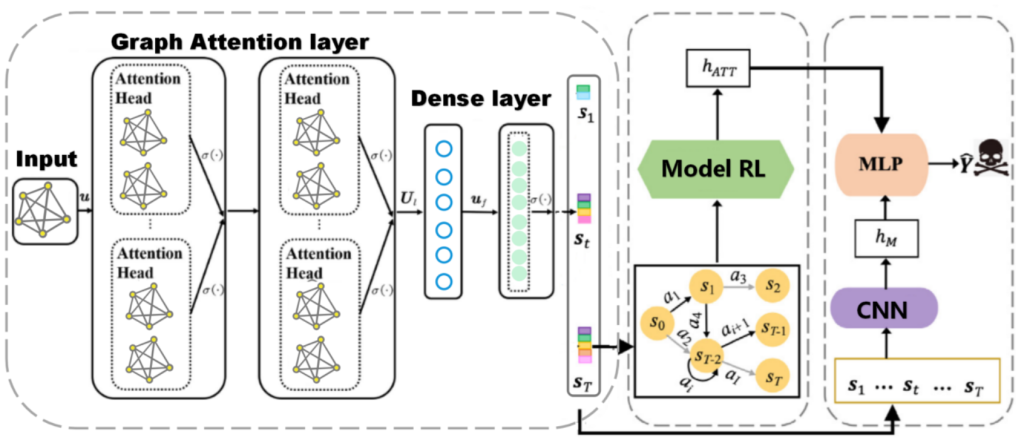
1.根据DERs系统物理结构信息,我们提出一个图表示学习方法,这种方法能够捕获新的结构状态信息,从而提高检测效率。
2.根据物理—信息这种复杂动态系统,采用马尔可夫决策流程 (MDP) 来有效地对网络攻击行为进行建模,并通过与从少量观察到的数据中得出的最佳奖励,自主探索内在的攻击意图,提高检测效果。
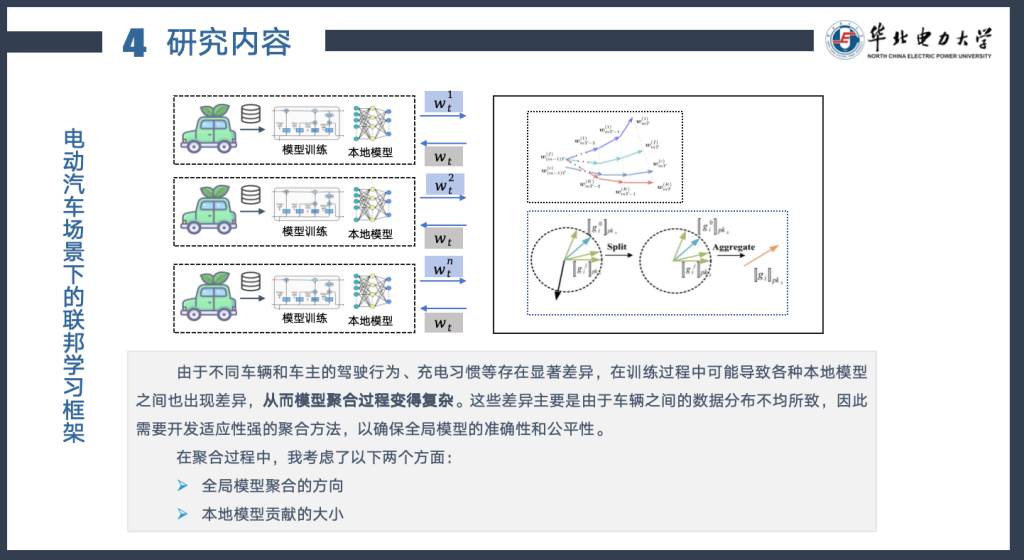
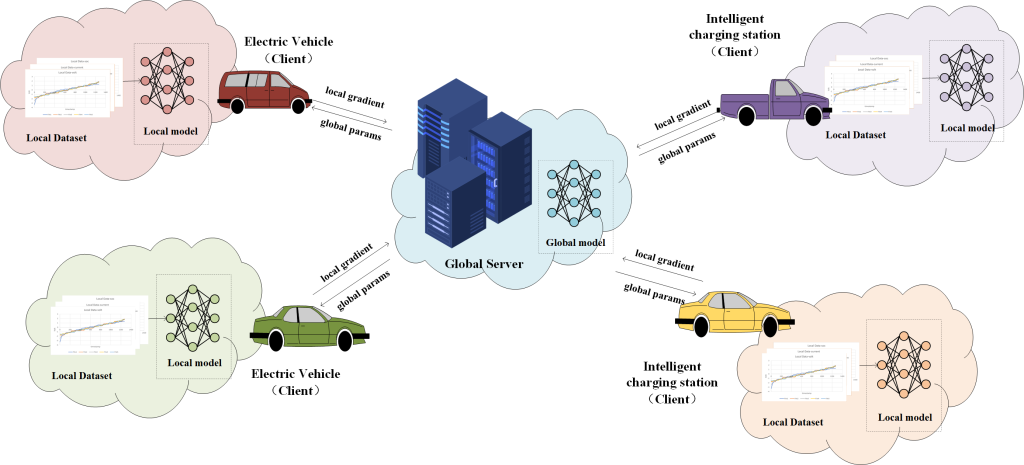
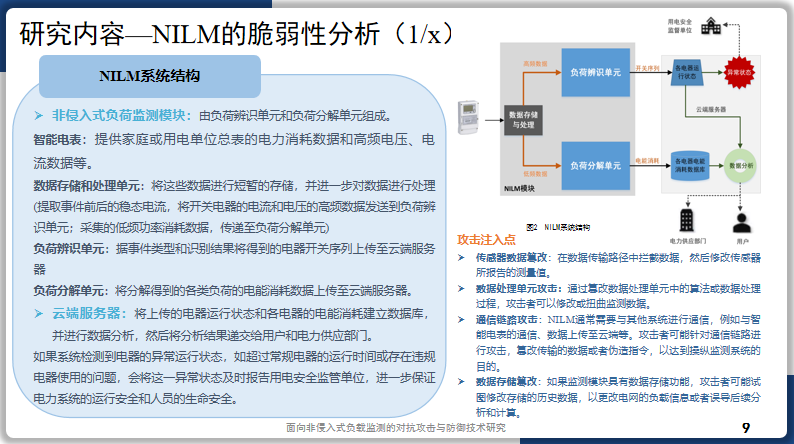
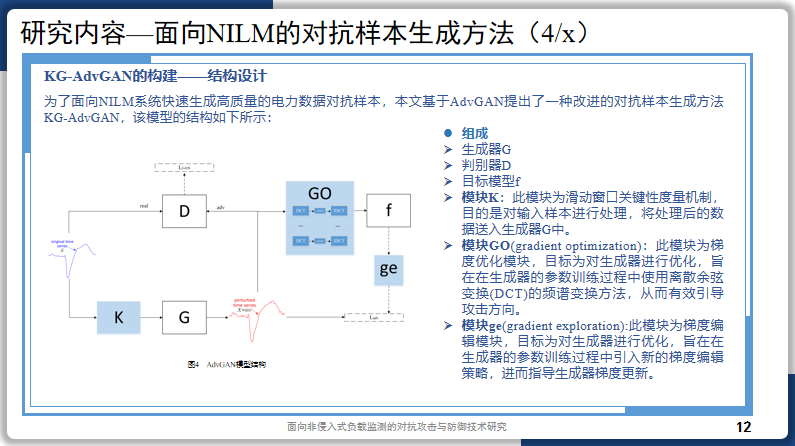
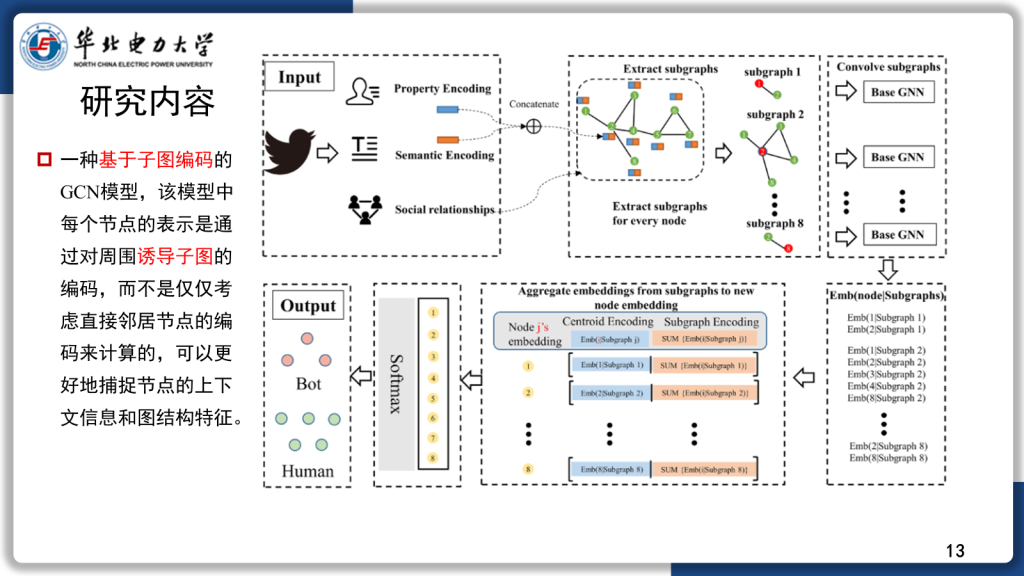
研究内容