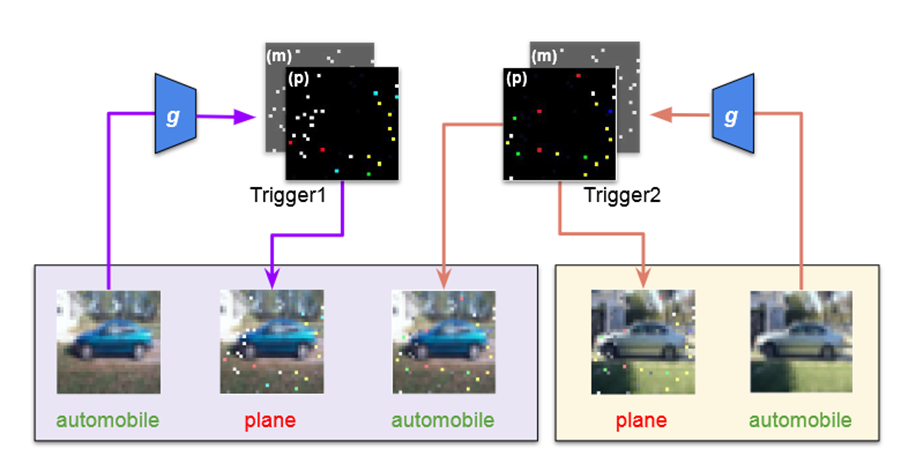
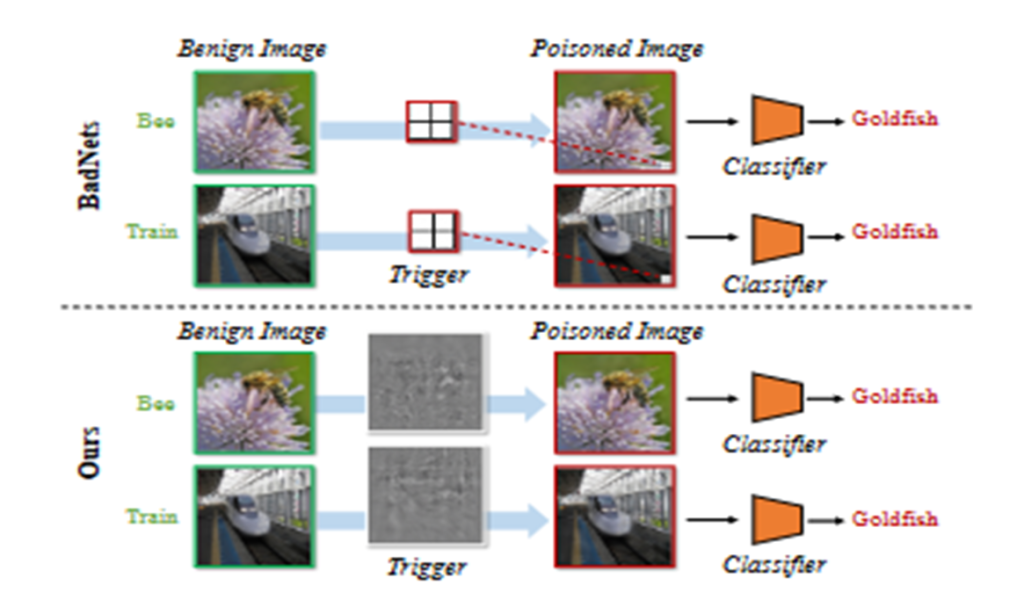
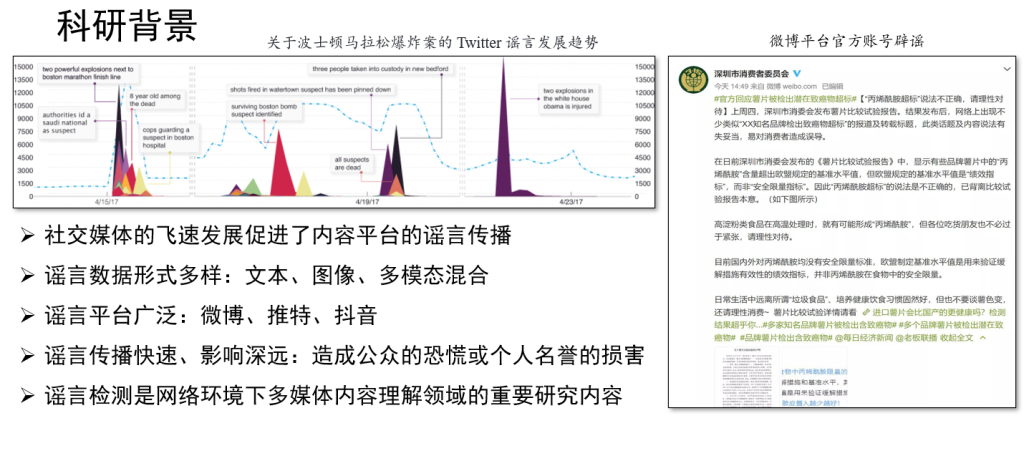
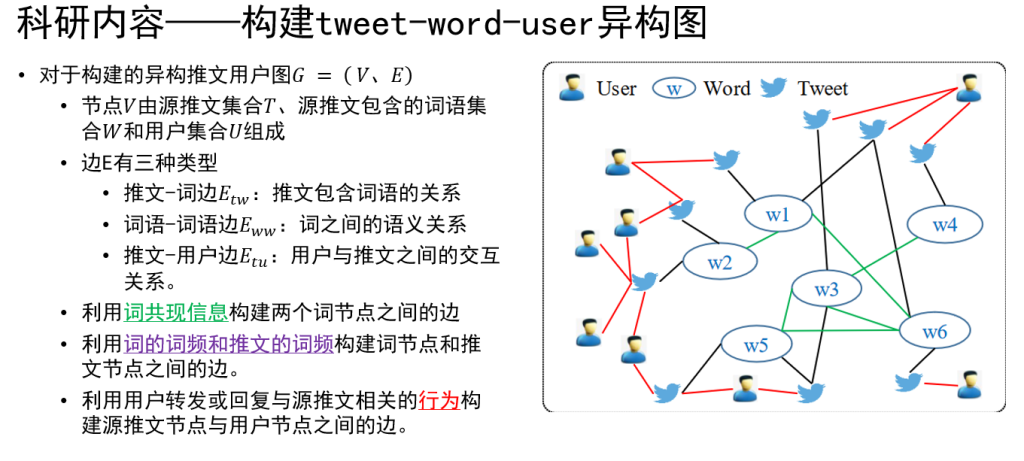
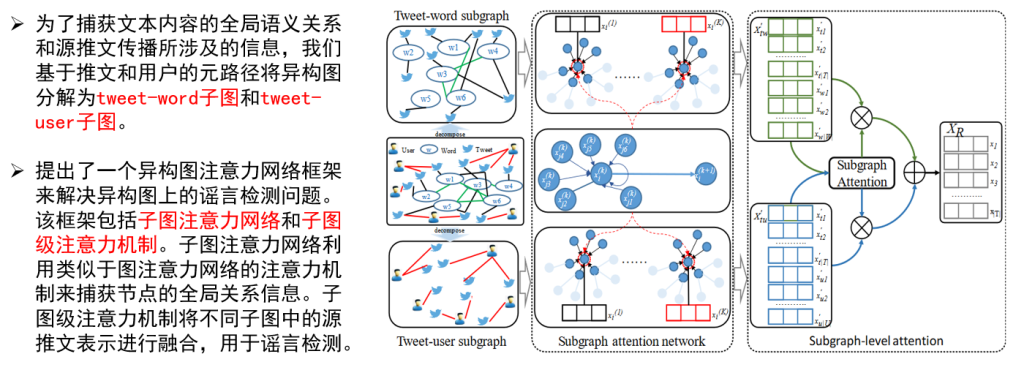
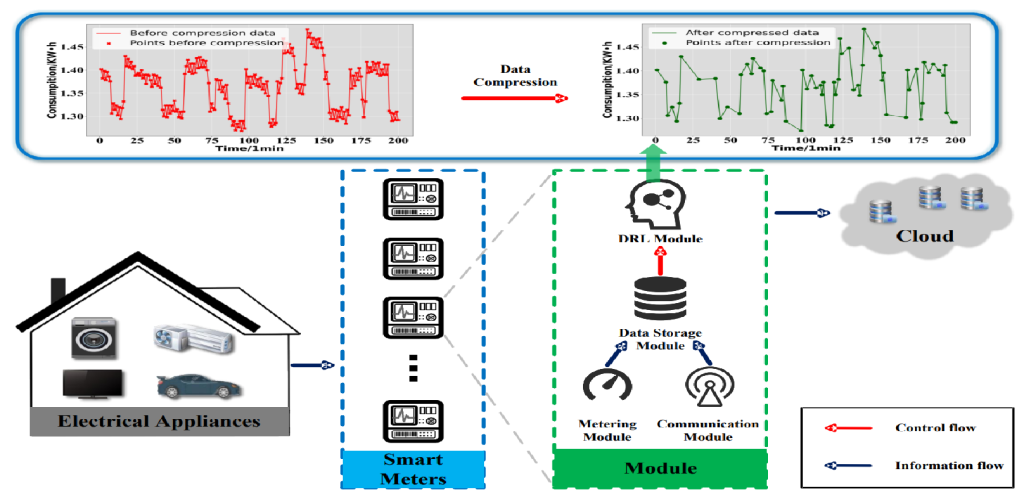
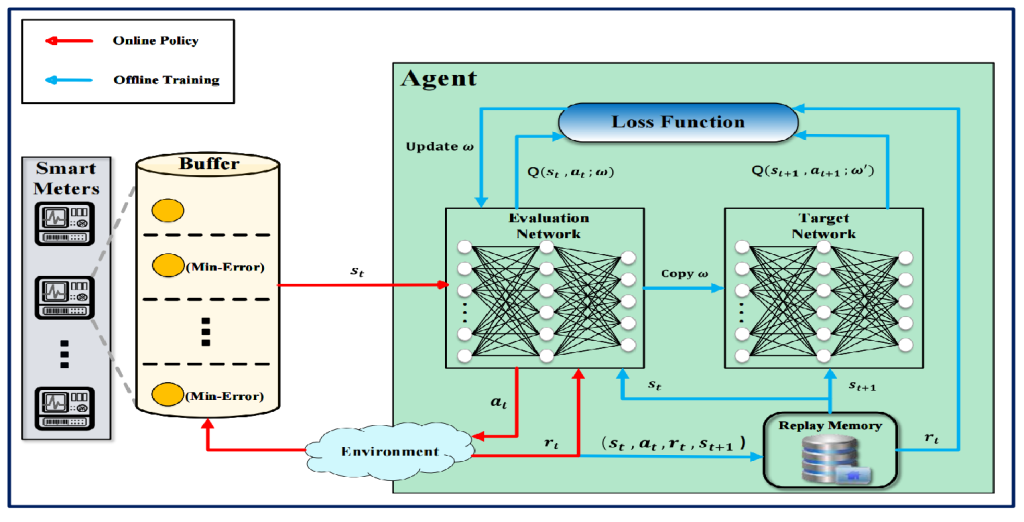
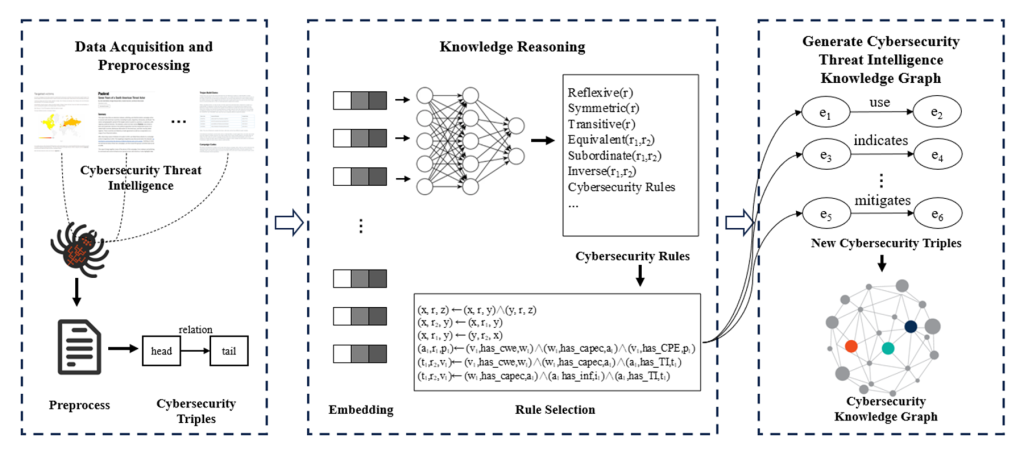
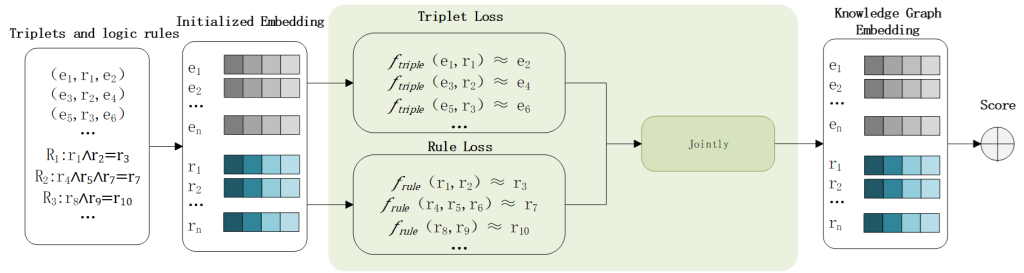
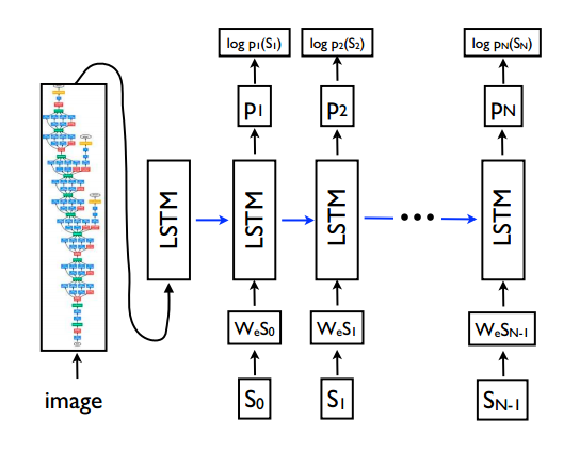
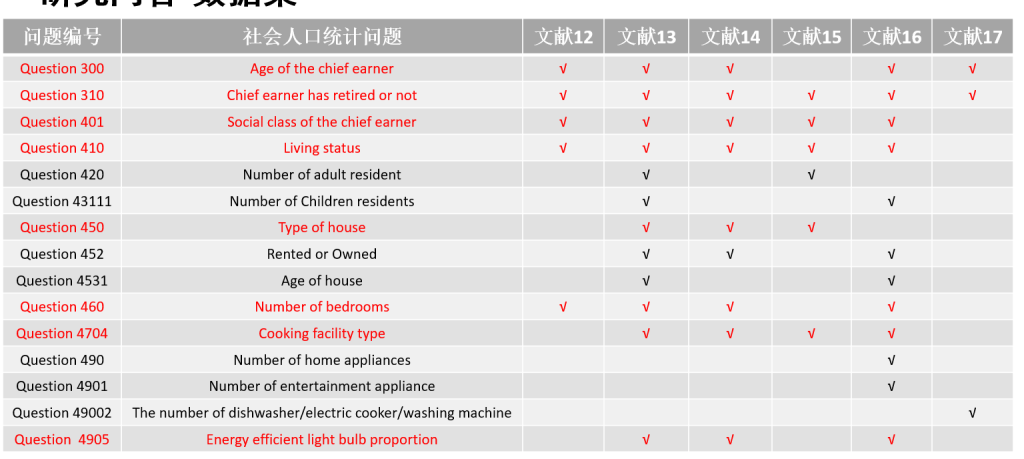
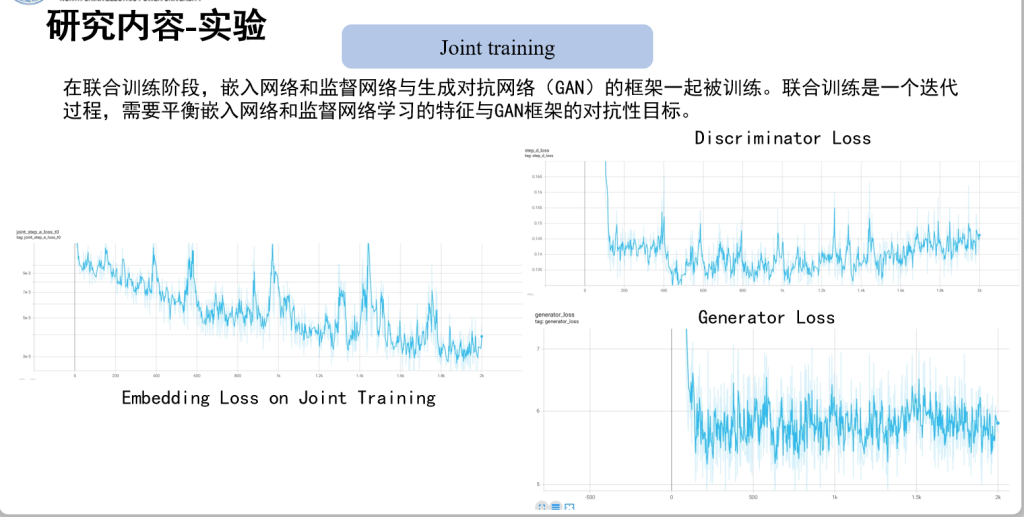
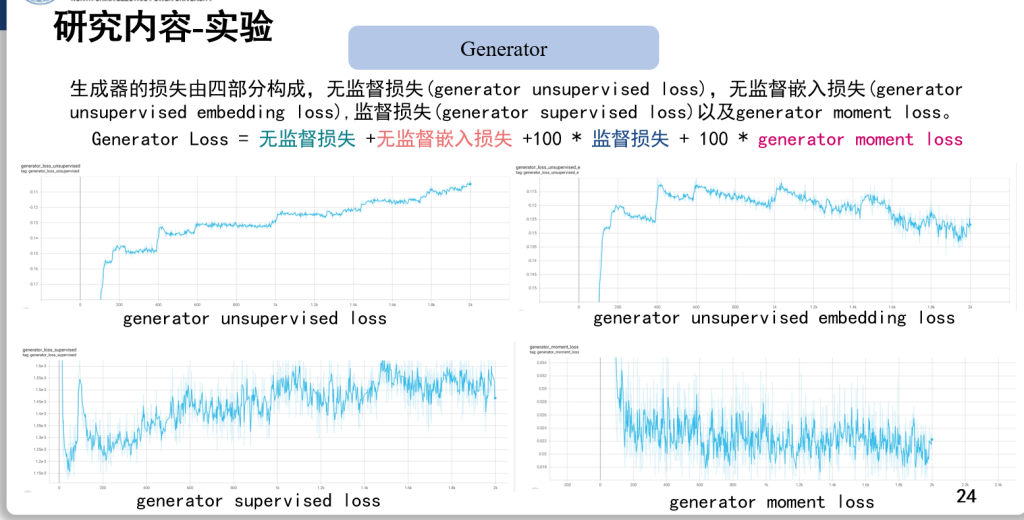
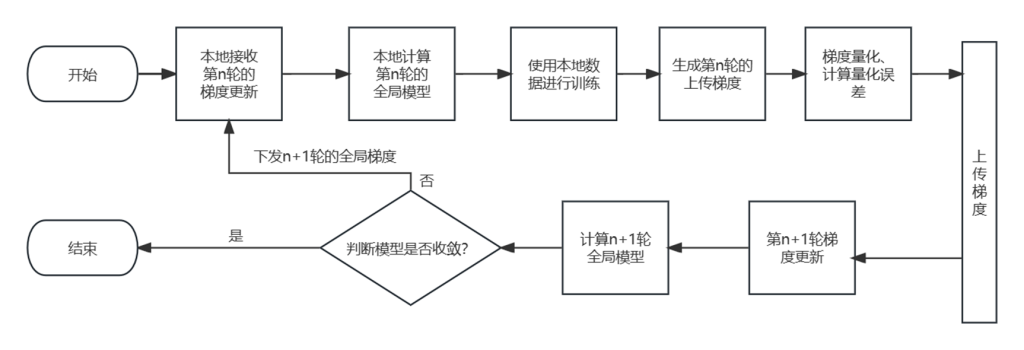
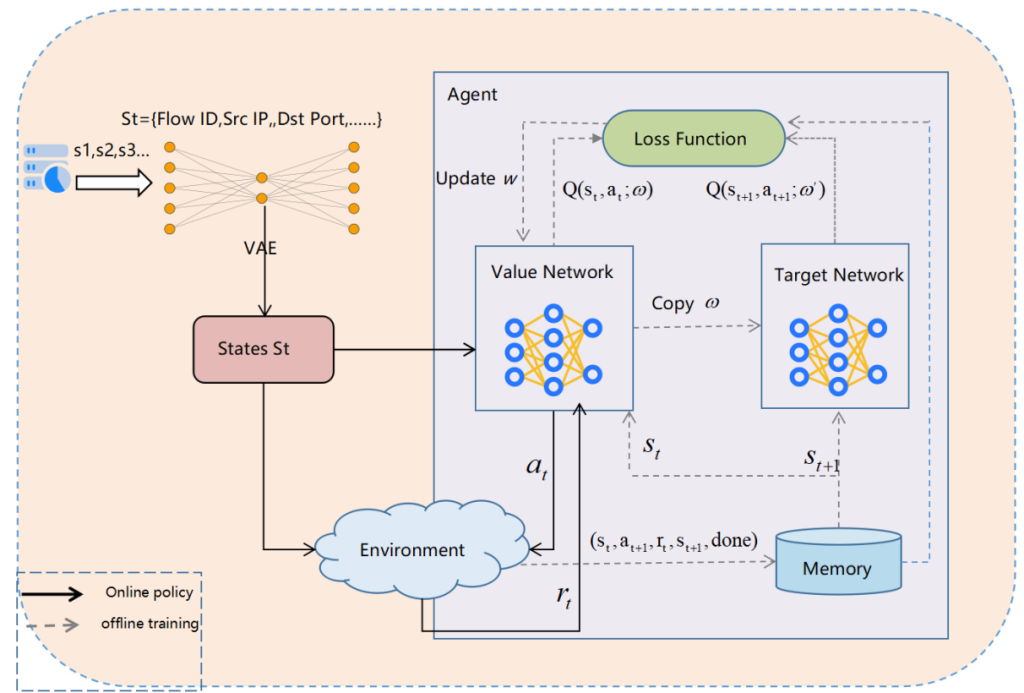
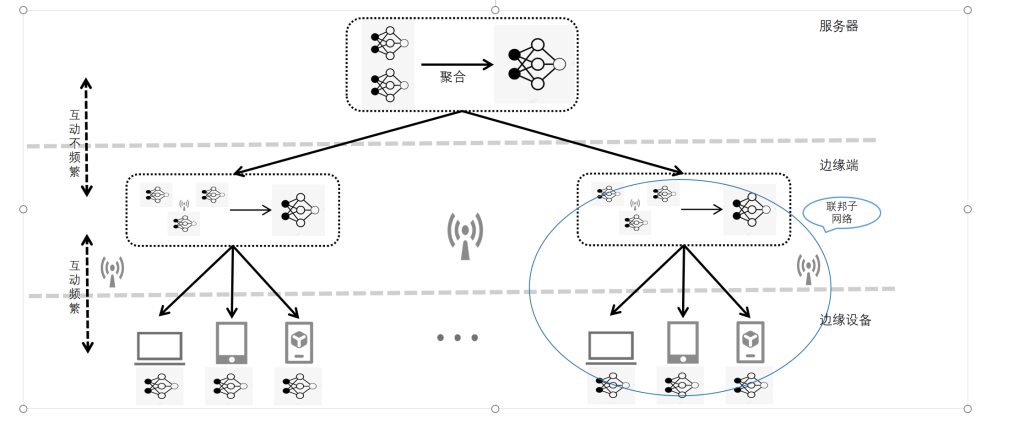
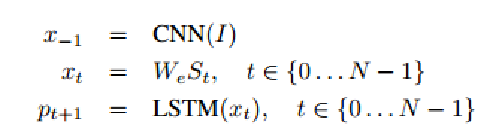虚拟电厂(Virtual Power Plant,VPP)是一种集成多种分布式能源资源(Distributed Energy Resource,DER)的系统,通过智能化的技术和管理,实现分布式电源DG(distributed generator)、储能系统、可控负荷、电动汽车等DER的聚合和协调优化,以作为一个特殊电厂参与电力市场和电网运行的电源协调管理系统。虚拟电厂概念的核心可以总结为“通信”和“聚合”。将这些资源整合成一个统一的虚拟实体,以提供电力服务、优化能源利用并支持电力系统的稳定运行,通过协调和优化各种分布式能源设备,实现对电力市场的参与和能源管理的最大化于,对保障电力系统的安全稳定运行具有重要意义。其中每个分布式能源主体产生了大量数据,在当前日益严格的隐私保护法案监管下,不适合将数据上传到云端进行集中式处理,各主体设备的数据通常只能在本地进行,收集、处理、分析和使用这些数据来做出决策和确定行动需要带宽、足够的处理能力和速度,这种处理方式效果十分有限。