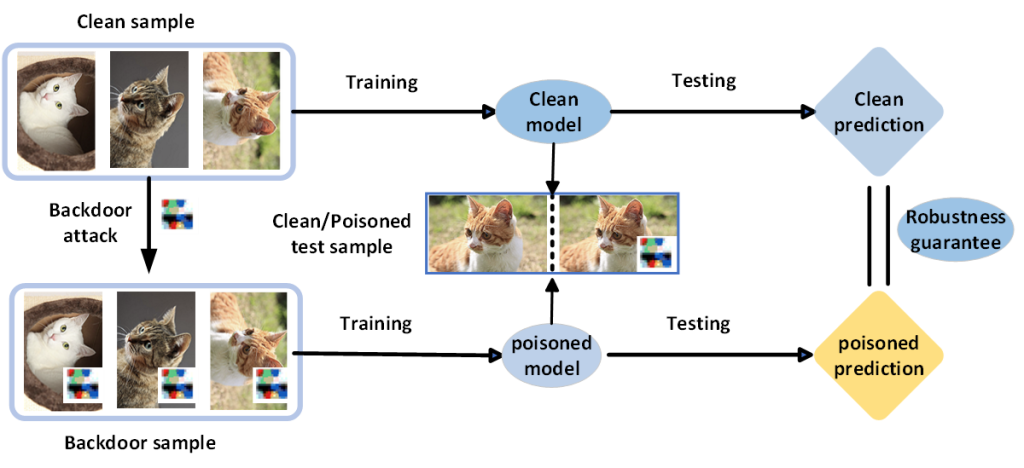
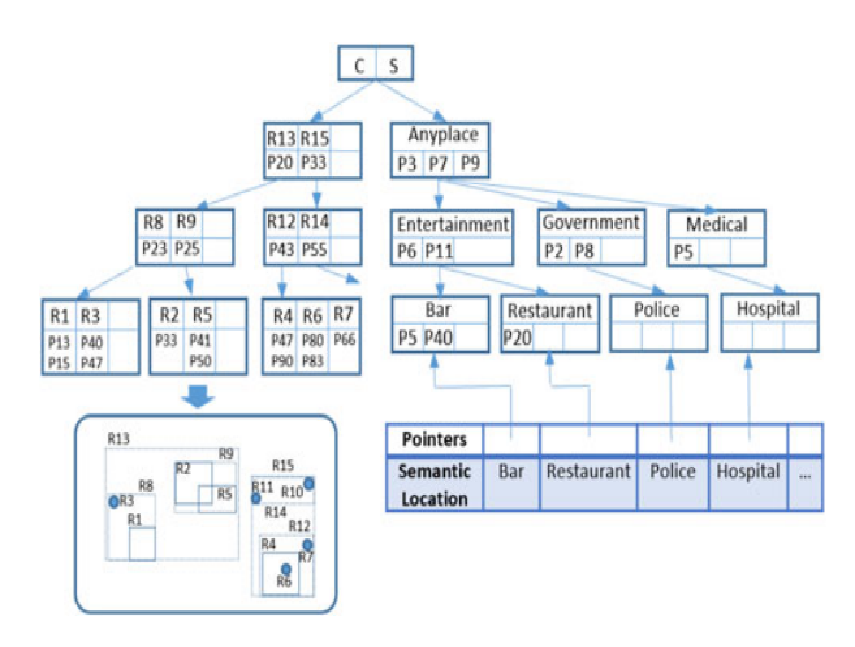
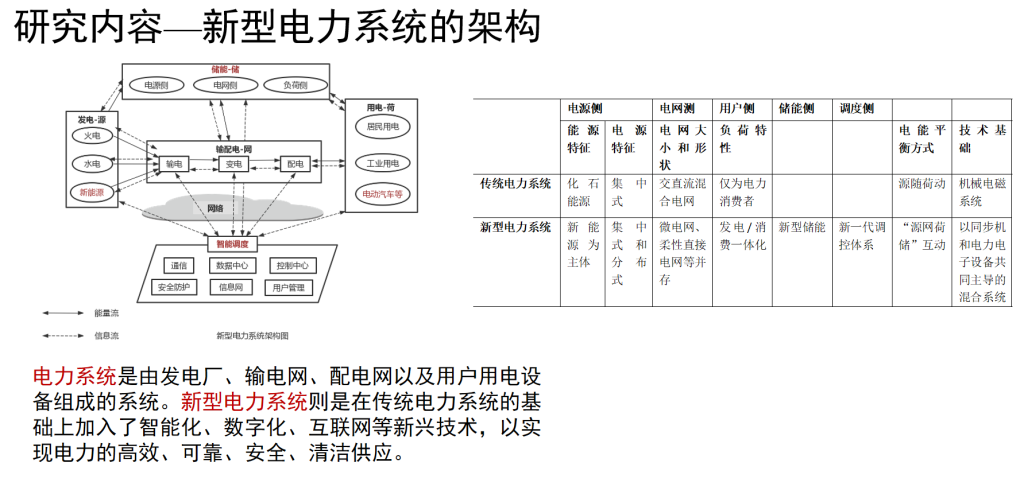
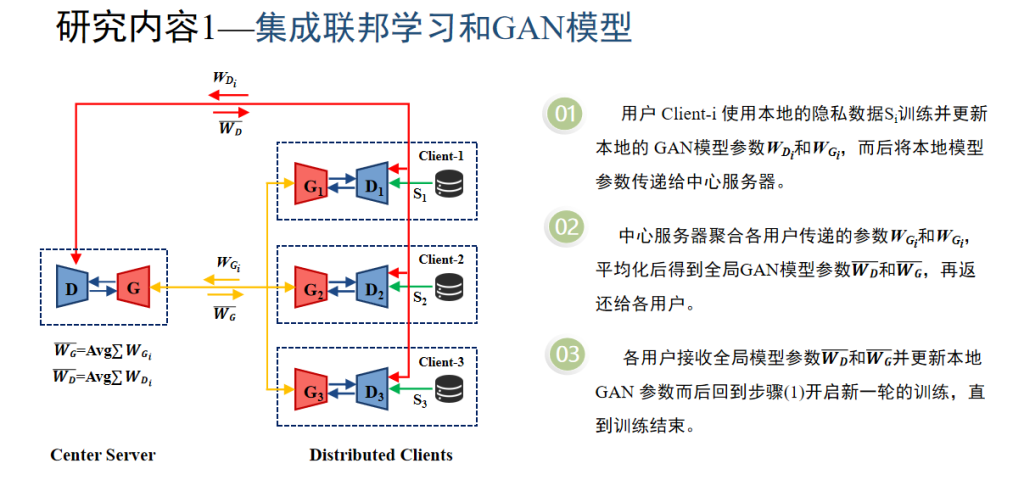
本次组会介绍面向联邦学习的类别隐私推理攻击
科研背景
联邦学习实质上是深度学习和分布式计算的结合。在联邦学习中,参与方(客户端)拥有各自的私有数据,而服务器负责协调模型的训练,但不能直接访问客户端的数据。
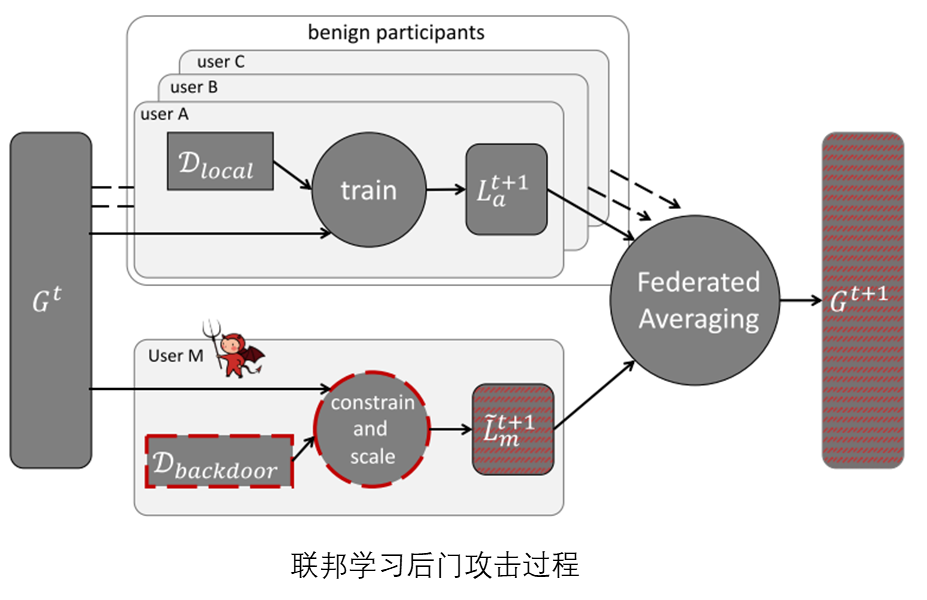
中间梯度可以用来推断有关训练数据的重要信息,为了避免联邦学习中模型更新的泄漏,提出了安全聚合协议,通过伪随机值掩盖这些数值,以确保没有人可以看到清晰的提交更新。聚合服务器也只能在每一轮训练中获得聚合结果。
攻击者可能通过与一些恶意客户端(间谍)合谋,来窥探其他客户端的私有数据。推理攻击是指攻击者通过某些攻击手段来获取模型的某些信息(如数据集、更新的参数等),来推理获取目标信息。类别推断攻击,旨在推断目标客户端所拥有的数据类别。
科研问题
联邦学习系统极易遭受由恶意参与方在预测阶段发起的成员推理攻击行为,并且现有的防御方法在隐私保护和模型损失之间难以达到平衡。
科研目的
深入研究联邦学习中的推理攻击方法,提高攻击成功的可能性。
针对具体的推理攻击,设计对应防御方法,进行隐私保护和防御。
研究内容
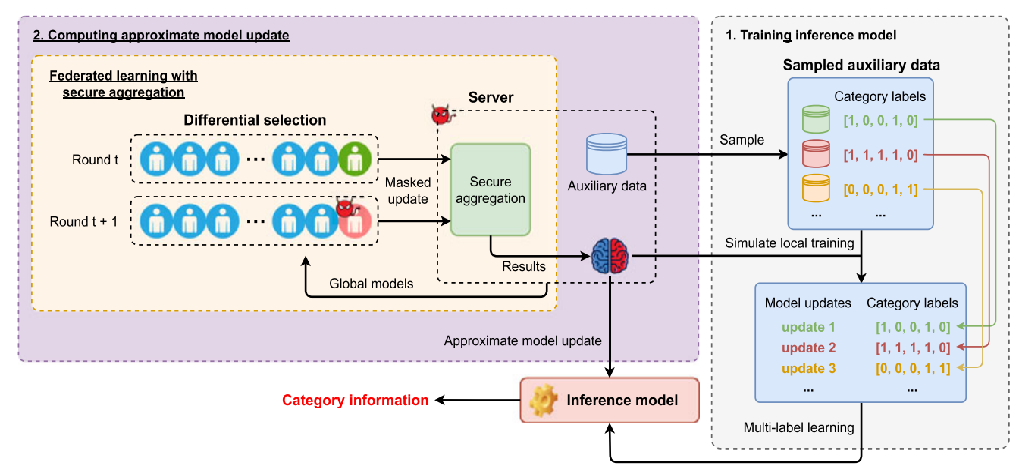
1、提取目标客户端的模型更新
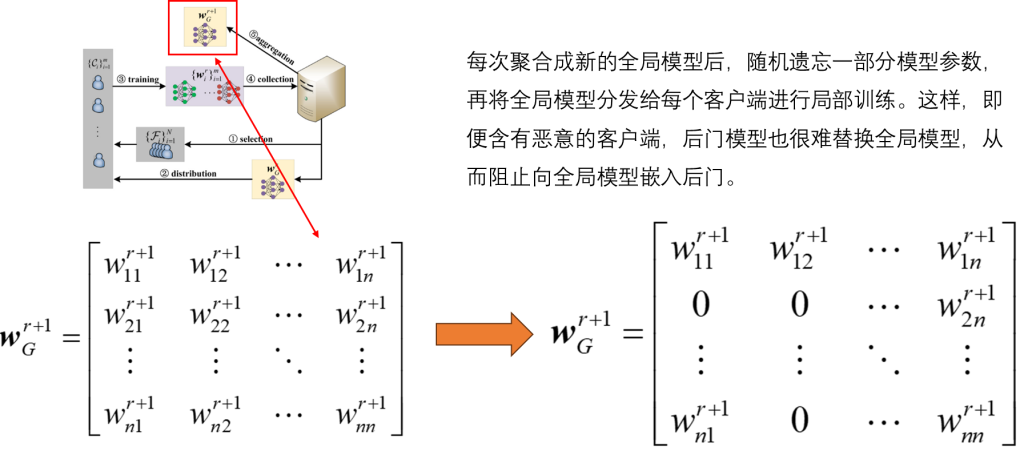
由于安全聚合,无论是服务器还是客户端都无法访问明确的模型更新。通过差分选择策略,通过选择两个相邻的客户端集,二者仅在一个客户端上有所不同,这个差异的客户端(即被替换的客户端)起到了”间谍”的作用。
近似更新与真实更新之间的差异为“噪声”。其会降低攻击性能。为了减轻噪声的负面影响,提出了两种去噪方法。第一种方法是设置一个噪声记录器,模拟训练过程中的噪声。第二种方法是实施重复攻击,以获得多个预测并选择最可能的结果。
2、训练推理模型来预测目标客户端持有的类别
可以通过构建pair<类别更新:类别标签>的数据集,并使用多标签学习来训练一个推理模型,该模型将单个模型更新映射到其对应的类别。
多标签学习是一种机器学习范式,它允许一个数据实例被分配到多个标签,而不仅仅是单一标签。在多标签学习中,每个数据点可以同时属于多个类别。
多标签学习中的一个多标签数据实例(x;Y)由一个数据点x和一个二进制多标签向量Y = (y1, y2, … , yK) 组成,其中K是类别的总数。每个yi表示数据点x是否与相应的第i个类别相关联。
3、隐藏攻击
使类别推理攻击更不显眼,不被诚实的客户端注意到。该攻击可能通过检查两轮中攻击者选择的客户端集之间的相似性被检测出来。如果两轮选择的客户端集过于相似,诚实客户端可能会察觉到被攻击。
因为不同的客户端可能有不同的数据分布、特征和更新,在多轮训练中会表现出多样性。需要采取措施使其选择的客户端集合更随机,模拟正常的联邦学习行为,从而避免引起系统的怀疑。
5、攻击过程
第一步是训练一个多标签推理模型,服务器端攻击者可以构造两个相邻的客户端集合,客户端攻击者复制当前全局模型,基于准备的辅助数据来模拟目标客户端的本地训练过程。一旦获得足够数量的模拟更新,攻击者可以构建一个新的数据集,用于训练推断模型。

研究计划
研究联邦学习多种场景下的推理攻击方法,复现实验进行验证。
对于特定场景中的推理攻击方法,设计基于差分隐私、对抗训练等技术的防御策略,并进行实验验证。